開く
目次
第4章
RAGエージェント|次世代RAGアーキテクチャと回答精度検証
RAGエージェント|次世代RAGアーキテクチャと回答精度検証
第2章の利用動向分析では、利用者の質問が単一の情報探索から、複数の文書を横断的に参照し統合する必要がある「複合的なクエリ」へと質的に高度化していることが明らかになった。この変化は、一度の検索で回答を生成する従来型のRAGアーキテクチャでは対応が困難であるという、新たな技術的課題を浮き彫りにした。本章では、この課題に対し、どのような技術的アプローチが有効であるかを比較検証によって実証することを目的とする。
利用者が直面する問題は、単一文書の参照のみでは解決せず、複数のマニュアルに分散した情報を横断的に調査したり、エラーメッセージとその発生状況を照合して原因を推論したりするなど、高度な情報統合能力を必要とするものが少なくない。この要求に応えるため、当社は従来のRAGアーキテクチャを問い直し、AIエージェントが質問を複数のサブクエリに分解し、自律的・再帰的に情報を探索・統合する、いわゆる「Agentic RAG」と呼ばれる仕組みを独自に実装した。本レポートで検証するAskDonaの最新バージョン(dona-rag-2.0 および dona-rag-2.5)は、この新しいアーキテクチャに基づいている。
AskDonaの2つの最新バージョンは、データソースの事前処理方法に違いがある。「dona-rag-2.0」は、OCRによる高精度な文字・表認識を特徴とする。一方、「dona-rag-2.5」は、dona-rag-2.0の機能に加え、文書内の図やグラフといった視覚情報の内容をテキスト化し、検索対象に含める機能を備えている。
本検証では、情報の正確性に加え、複数文書にまたがる横断的な調査や専門的な推論といった高度な要求に対し、AskDonaの最新バージョン(dona-rag-2.0 及び dona-rag-2.5)と主要なRAGがどの程度の性能を発揮できるかを評価する。具体的に広く利用されているクラウドプロバイダーのサービス(Microsoft社 Azure AI Search、Google社 Vertex AI Search、Amazon社 Amazon Bedrock)とオープンソースフレームワークはLangChainを用いてRAGシステムを構築した。
全システムには、PDF、CSV、HTML形式を含む「富岳」の専門文書239点(合計約16,000ページ以上)を同一のRAGのデータソースとして利用した。そして、「富岳」の運用に携わるR-CCSの専門家が、実際の問い合わせ傾向を反映して選抜した25問の「複合的な質問」を評価用の質問セットとして用いた。各システムが生成した回答の品質は、R-CCSの専門家による厳密な「人的評価」を通じて評価し、その回答精度を検証した。
以降のセクションでは、この検証の具体的な設計(2.1)、評価手法(2.2)、そしてその結果(2.3)について詳述する。
4.1 検証の設計と評価方法
本節では、比較検証の公正性と再現性を担保するために設定した各RAGシステムの構築条件について詳述する。本検証では広く利用されているクラウドプロバイダーのサービスが提供するRAGシステムとオープンソースフレームワークをAskDona(dona-rag-2.0 及び dona-rag-2.5)の比較対象として選定した。具体的には、Microsoft社のAzure AI Search、Google社のVertex AI Search、Amazon社のAmazon Bedrock、そしてオープンソースソフトウェア(Open Source Software、OSS) であるLangChainを用いて、4つのRAGシステムを構築した。
検証にあたり、AskDonaがRAGのデータソースとするPDF、 CSV、 HTML形式を含む「富岳」の専門文書239点(合計約16,000ページ以上)を全ての比較対象システムに同一のデータセットとして利用した。
RAGシステムの構築には、チャンク分割の手法、Embeddingモデルの選定、検索アルゴリズムのパラメータといった、調整可能な変数は多数存在する。これらの組み合わせは膨大であり、特定の条件下で性能を最大化するためのチューニングが可能である。
しかし、本検証の目的は特定のシステムを極限までチューニングすることではなく、異なる技術アプローチの基本的な性能を公正に比較することにある。そこで、各比較対象システムは、それぞれのプロバイダーが推奨する設定や広く認知されたベストプラクティスに基づき、標準的でありながら高い性能が期待できる状態へと最適化を行った。
各システムの性能を最大限に引き出すため、構築にあたってはAskDona(dona-rag-2.0 及び dona-rag-2.5)を除くシステムについて以下の共通方針を定めた。共通方針に基づき構築された各システムの概要と設定条件は表4.1の通りである。
同一データソースの利用: 全てのシステムで、全く同じ専門文書群をデータソースとして使用する。
高性能モデルの採用: 回答生成には各プラットフォームで利用可能な高性能な生成モデルを採用。Embeddingには高次元のモデルを優先的に採用する。
検索件数(Top-K)の統一: 回答生成の根拠として参照する文書チャンクの数を揃えるため、検索件数(Top-K)は全てのシステムで10件に統一する。
チャンク手法の標準化: 多くのクラウドプロバイダーが固定長のチャンク分割を標準としているため、本検証でも固定長チャンキングを基本とし、各プロバイダーの推奨設定またはデフォルト値に従う。
再現性の確保 (temperature設定): 回答の揺らぎをなくし、再現性を担保するため、生成モデルのtemperatureは原則として0に設定する。
最善なテキスト抽出手法の選択: OCR処理が適用可能な場合は必ず実行し、テキスト抽出の精度を高める。
指示プロンプトの統一: 各システムに与える指示プロンプト(システムプロンプト)は、条件を揃えるため全て同一のものを使用する。
ベクトルインデックスの作成: 検索効率と精度を高めるため、ベクトルデータのインデックスを必ず作成した。
表4.1:比較対象RAGシステムの構築条件詳細
RAGシステム | Microsoft社 Microsoft Azure(Azure AI Search) | Google社 Google Cloud (Vertex AI Search) | Amazon社 | LangChain (OSS) |
主要サービス | Azure AI Search, Azure OpenAI | Vertex AI Search | Bedrock KB, OpenSearch, S3 | FAISS (CPU), OpenAI API |
生成モデル | GPT-4o | Gemini 2.0 Flash | Claude Sonnet 4 | GPT-4o |
Embeddingモデル | text-embedding-3-large | text-embedding-004 | amazon.titan-embed-text-v2:0 | text-embedding-3-large |
ベクトル次元数 | 3072 | 768 | 1024 | 3072 |
チャンク手法 | サイズ: 2000文字 オーバーラップ: 500文字 | サイズ: 1000文字 オーバーラップ:100文字 | サイズ: 300トークン オーバーラップ: 20% | サイズ: 1000文字 オーバーラップ:200文字 |
検索手法 | ハイブリッド検索 | ベクトル検索 + キーワード検索 | ベクトル検索 | 近似近傍探索 (FAISS) |
OCR処理 | Azure AI Vision (Skillset) | Vertex AI Search (Built-in) | なし (S3からの直接取込), マルチモーダルモデルへの画像認識 | Tesseract (unstructured) |
4.2 評価用質問セットの選定
本節では、前節で構築した6つのRAGシステム(AskDona dona-rag-2.0、dona-rag-2.5 および比較対象4システム)の回答精度を測定するために用いた、評価用質問セットの選定基準について詳述する。
本検証で用いる質問セットは、情報の正確性に加え、複数文書にまたがる横断的な調査や専門的な推論といった高度な要求が求められる富岳サポートサイトの環境を例として、実際にAskDonaに送信された利用者質問(クエリ)の傾向を分析し、その結果に基づいて設計した。
特に、表4.2-1に記載される定義に沿った質問を25つの質問を厳選した。これらの質問は、検索された単一の情報を要約するだけでは回答できない質問や一般的なRAGシステムが構造的に回答生成を困難とする質問(複合的なクエリ)、およびユーザーによる入力間違いを含む質問である。
表4.2-1:評価用質問セットの定義
質問カテゴリ | 定義 |
情報統合性能を問う質問(複合的なクエリ) | 単一の情報源だけでは回答できず、複数の文書にまたがる情報を多角的な視点から横断的に探索・統合し、論理的に再構成する必要がある質問。 |
高精度な検索(リトリーバル)性能を問う質問 | 類似する情報やエラーコードが多数文書内に存在し、その中から最も関連性の高い情報を正確に特定する能力が求められる質問。 |
曖昧・不完全な入力への対応性能を問う質問 | 質問文に誤字脱字が含まれる場合や、質問の意図が不明確で、システム側が利用者の真の要求を推論・解釈する必要がある質問。 |
意味理解と類推性能を問う質問 | 質問で使われている言葉が、データソースとなる文書内に直接存在しない場合でも、意味的な類似性や文脈から関連情報を特定し、紐付ける能力が求められる質問。 |
情報の有無を正確に判断する性能を問う質問 | データソースに「存在する内容」と「存在しない内容」が混在している場合に、存在しない情報を正確に特定し、「その情報はない」と回答に含めることができるかを評価する質問。 |
本検証で用いる質問セットの内容は実際AskDonaに送信された質問を利用しているため、図4.2-2に参考情報として公開可能な質問例を公開する。図4.2-2の質問は、実際に富岳サポートサイトのAskDonaでよく受け付けるエラーメッセージに関する質問である。AskDonaの初期バージョン(dona-rag-1.0)は、ユーザーの質問に対して適切な回答を生成するものの、質問文に質問の背景や前提が不足している場合には、的確な回答が得られにくいという特性があった。一方、AskDona(dona-rag-2.0)は、ユーザーの質問意図を過去のチャット履歴から解釈してサブクエリ化、AIエージェントが自律的かつ再起的に情報を調査・取得したりすることで、より的確で網羅性の高い充実した回答生成を実現している。
図4.2-2:単一の情報を要約するだけでは回答できない質問例
4.3 本検証における評価アプローチと評価基準の選定
本節では、前節で厳選された25問の質問セットを評価するための評価手法について詳述する。
本検証の評価を決定するにあたり、既存のRAGシステム評価手法を検討した。近年、RAGシステムの性能を自動で評価する試みとして、いくつかのフレームワークが提案されている。例えば、生成された回答の忠実性(Faithfulness)や関連性(Relevance)等を定量化するRAGAs (Es et al., 2023) や、公開QAデータセットを用いてスコアを競うRAG-QA Arena (Lee et al., 2024)といった取り組みがある。これらの自動評価手法は、標準的なRAGプロセスの性能を迅速に把握する上で一定の有用性を持つ。
しかし、本検証では、専門家の知見に基づく人的評価が最も妥当なアプローチであると判断した。その理由として、まず評価対象である「AskDona」が、質問をサブクエリに分解したり、エージェントが自律的・再帰的に情報を探索したりする独自のアーキテクチャを持つ点があげられる。このような複雑な情報処理は、既存の自動評価フレームワークが前提とする単純なプロセスとは異なり、その性能を十分に評価しきれない可能性がある。さらに、本検証の目的でもある社会実装の促進のために必要な「実用性(Practical Utility / Helpfulness)」を専門家の視点から評価することが重要と考えた。この指標は、回答の納得感や問題解決への直接的な貢献度といった、現状の自動評価手法では測定が難しい側面を含む。これらの点を総合的に勘案し、今回の検証では専門家による人的評価を通じて、システムの有効性、特にその実用性や回答の質を深く測定するアプローチを採用した。この人的評価を実施するにあたり、客観性と信頼性を担保するため、以下の評価プロセスと評価基準を設計した。
◾️評価プロセスの設計
評価の客観性と信頼性を担保するため、厳格な評価プロセスを設計した。まず、評価は「富岳」の技術と運用に精通したR-CCSの専門家3名が担当した。評価対象としたのは、AskDona(dona-rag-2.0 標準モデル、dona-rag-2.5 視覚情報処理モデル)および、Microsoft Azure AI Search、Google Cloud Vertex AI Search、Amazon Bedrock、LangChain(OSS)で構築したRAGシステムの合計6つである。このうち、AskDonaを除く4つの比較対象システムは、第4.1節で詳述した構築条件に基づき用意された。
評価手順においては、評価バイアスを排除することを最優先とした。具体的には、どのシステムが生成した回答かを伏せた状態(ブラインド評価)で、各質問に対する6つの回答の順序をランダムに入れ替えて評価者に提示した。さらに、各評価者は独立して評価を行い、互いの結果を閲覧できない状態を確保することで、評価の独立性を担保した。
◾️評価基準の定義
評価には、前節の定義により選定された25問の質問セットを用いた。
各システムの回答に対し、以下の3つの評価指標をそれぞれ5段階でスコアリングした。評価指標は、RAGAsに代表されるRAG評価フレームワークの考え方を参考に、本検証に適当な評価項目を設定した。
正確性 (Accuracy / Factuality):
生成AIの基本的な信頼性に関わる最重要指標である。情報の正確性は利用者の信頼に直結するため、事実に基づいた回答を生成する能力を厳格に評価する。これは、RAGAsにおける Faithfulness(回答が文脈に忠実か)の概念を包含した。
網羅性 (Completeness / Comprehensiveness):
利用者の質問に対し、回答が必要な情報をどの程度抜け漏れなく含んでいるかを評価する。特に複合的な質問では、複数の情報源から関連情報を集め、適切な推論や要約をすることが求められる。これは、RAGAsにおける Contextual Recall(検索された文脈が正解を網羅しているか)と Answer Relevancy(回答が質問の全ての側面に適切に応えているか)の概念を包含した。
実用性 (Practical Utility / Helpfulness):
回答が単に正しいだけでなく、利用者の問題解決に実際に役立つかを総合的に評価する指標である。これには、RAGAsの Answer Relevancy(回答が質問に関連しているか)の観点に加え、専門家の視点から見た納得感、具体的なアクションへの貢献度、さらには専門用語の適切性や論理的整合性(ドメイン適合性)といった、より実践的な側面も含まれる。
これらの評価軸は、RAGシステム評価に関する研究で考慮される基本的な観点を網羅しつつ、本検証が重視する専門性と実用性を測るために調整されており、各システムの総合的な性能評価を行う上で妥当かつ十分なものであると判断した。
5段階のスコアリングについても評価指標の定義を以下の表4.3のように行った。
表4.3:評価指標の定義
評価指標 | 評価基準(5点) | 評価基準(3点) | 評価基準(1点) |
正確性 (Accuracy / Factuality) | 全ての事実が正確で、誤情報や幻覚(ハルシネーション)が一切ない。 | 一部に正確な情報も含まれるが、重要な誤情報や幻覚も散見される。 | 回答の大部分が不正確またはハルシネーション(幻覚)で構成されている。 |
網羅性 (Completeness / Comprehensiveness) | 必要な情報が完全に網羅され、全ての主張が参照元に明確に裏付けられている。 | 重要な情報の一部が欠落しているか、一部の主張の根拠が不明である。 | 質問の大部分に答えておらず、情報が著しく不足している。 |
実用性 (Practical Utility / Helpfulness) | 質問意図に完全に合致し、専門家にとって非常に納得感があり、問題解決に直接役立つ。 | 部分的には有用だが、意図から逸れる部分があるか、内容がやや分かりにくい。 | 質問意図を全く把握しておらず、ユーザーにとって全く有用ではない。 |
この評価設計により、各RAGシステムが持つ問題解決能力を、専門的かつ実践的な観点から評価することを目指した。表4.3の評価指標の定義に従い、任意のRAGシステムAとBから出力された回答の評価を行った例を図4.3に示す。システムAの回答は、参照元は、適切に取得してきているが、記載されている内容の具体性に欠けており結果的に実用的な回答として評価されない例である。それに対してシステムBは適切な参照元から具体的なジョブの実行スクリプトの提示や質問文からは判断できない想定されるうる複数の対処法の提示を行っているため正確性、網羅性、実用性含めて高い評価を受けるような例である。
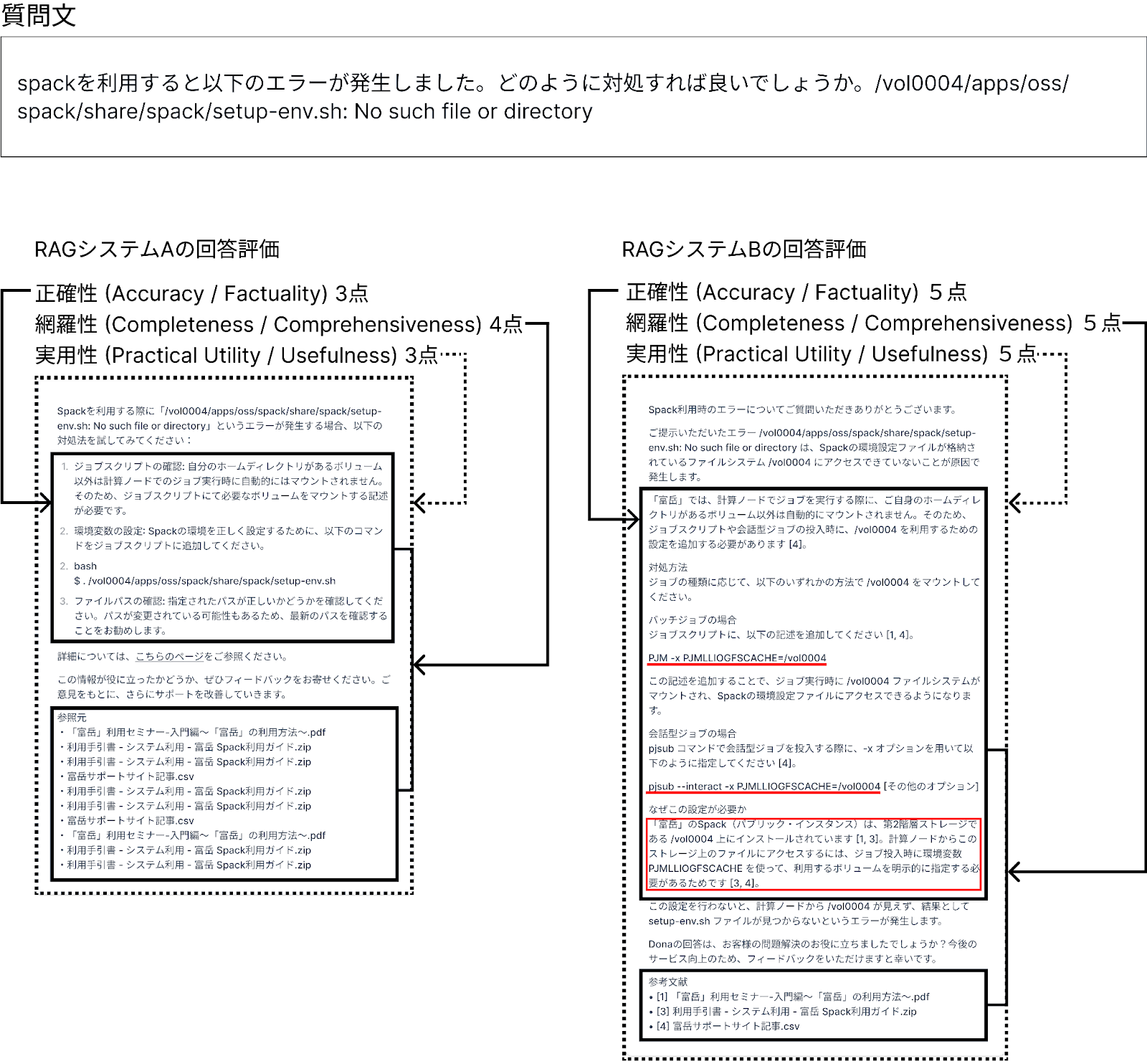
図4.3:各システムから出力された回答の評価例
4.4 回答精度評価結果
前節で設計した評価プロセスに基づき、6つのRAGシステム(AskDona dona-rag-2.0、dona-rag-2.5 および比較対象4システム)に対して25問の「複合的な質問」セットを用いた人的評価を実施した。本節では、その評価結果を報告し、考察する。
スコアは、3名のR-CCS評価者による25問への5段階評価(1〜5点)を各指標(正確性、網羅性、実用性)ごとに集計し、満点を100ポイント(pt)として正規化したものである。
図4.4-1は、各システムについて3つの評価指標(正確性、網羅性、実用性)の平均スコアを比較したものである。評価の結果、比較対象とした4システムのスコアは50ポイント台から70ポイント台前半の範囲に分布し、その総合平均は約61ポイントであった。これに対し、AskDonaはdona-rag-2.0が83ポイント、dona-rag-2.5が82ポイントとなり、比較対象の平均を20ポイント以上上回る結果となった。
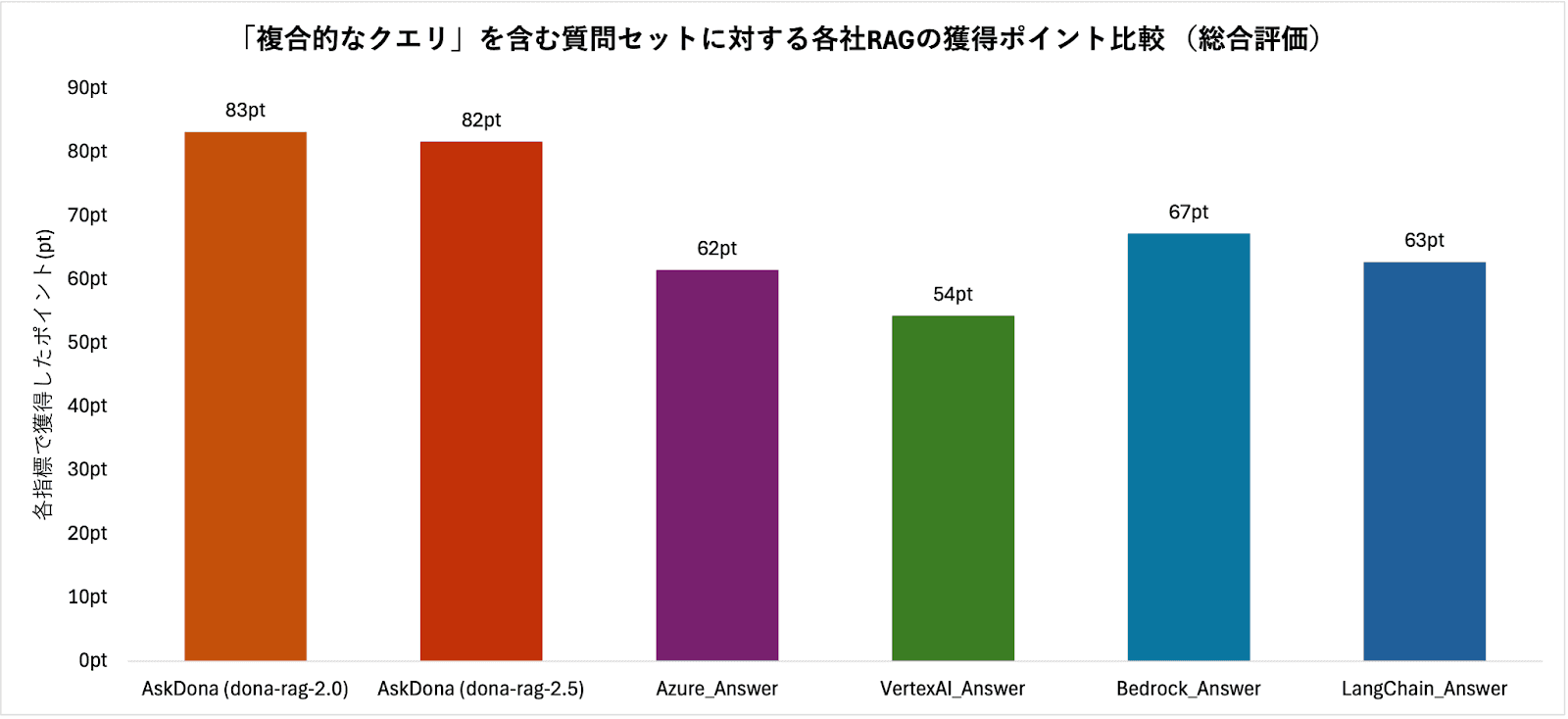
図4.4-1:「複合的なクエリ」を含む質問セットに対する各社RAGの獲得ポイント比較 (総合評価)
図4.4-2は、各システムについて3つの評価指標(正確性、網羅性、実用性)ごとのスコアを示したものである。AskDona(dona-rag-2.0)は、全ての比較対象を各指標で上回った。具体的には、主要なクラウドRAGサービスの一つであるAzure AI Search(正確性66pt、網羅性60pt、実用性58pt)に対して、正確性で18ポイント、網羅性で24ポイント、実用性で23ポイント上回った。比較対象の中で最も高いスコアであったAmazon Bedrock(正確性71pt、網羅性67pt、実用性63pt)に対しても、正確性で13ポイント、網羅性で17ポイント、実用性で18ポイント上回る結果となった。同様にLangChainやVertex AIに対しても、dona-rag-2.0が全ての指標で優位なスコアを記録した。
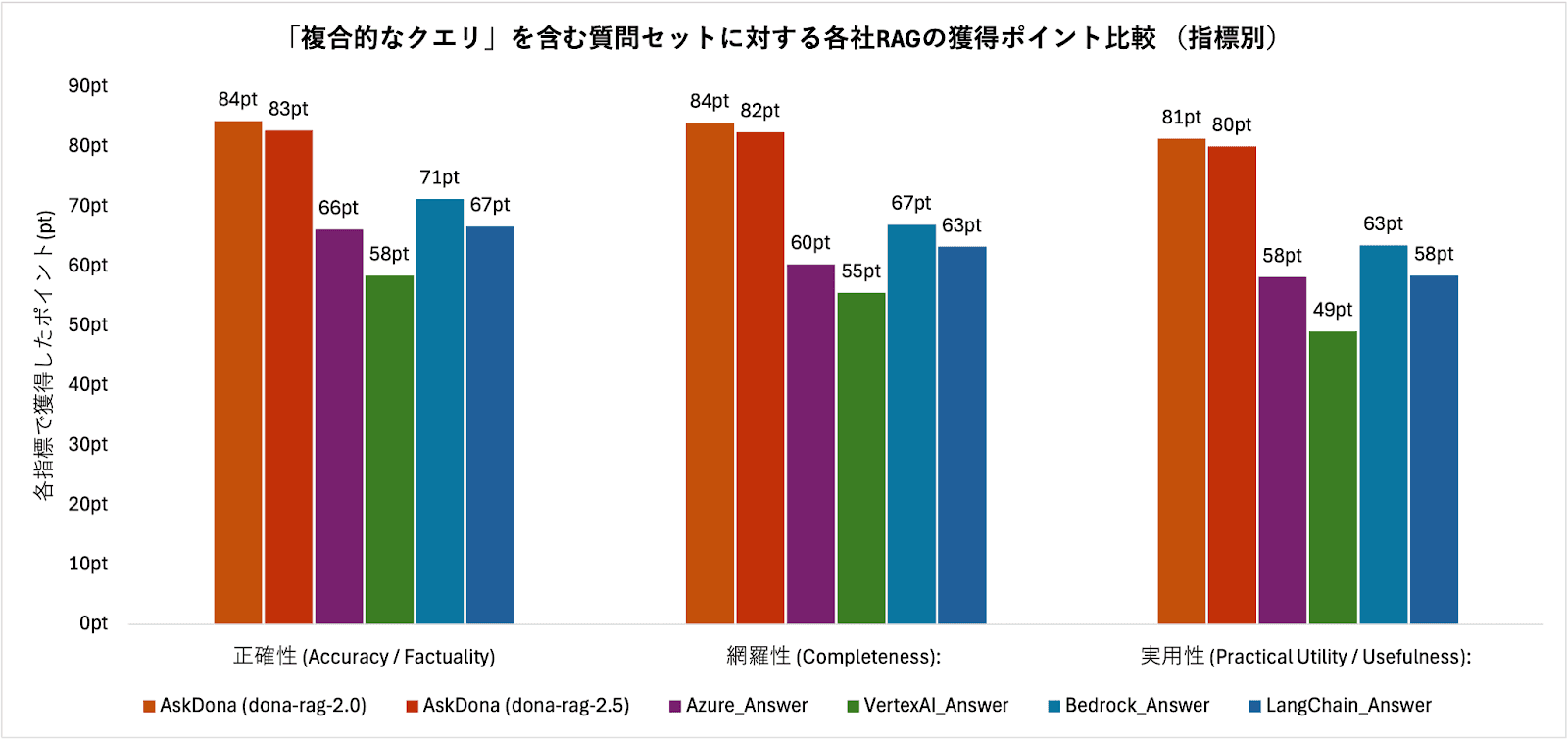
図4.4-2:「複合的なクエリ」を含む質問セットに対する各社RAGの獲得ポイント比較
今回の比較検証の結果、AskDonaは全ての評価指標において、比較対象とした4つのRAGシステムを上回るスコアを記録した。この結果から、いくつかの点が示唆される。
比較対象システムのスコアが最高でも70ポイント台前半に留まったのに対し、AskDonaはいずれのバージョンも80ポイント台のスコアを獲得した。この差は、最終的な回答品質が生成モデル(LLM)単体の性能だけでなく、RAGのアーキテクチャ全体に大きく依存することを示唆している。
この傾向は、比較対象内で最高スコアを記録したAmazon Bedrockの事例からも見て取れる。Bedrockは高性能なLLMを採用しているにもかかわらず、AskDonaはそれを全ての指標で上回った。これは、「複合的なクエリ」へ対応するためには、高性能なLLMを搭載するだけでなく、その能力を最大限に引き出すための高度なアーキテクチャ設計が不可欠であることを裏付けている。
なお、dona-rag-2.0(文字や表情報のみ)が、dona-rag-2.5(視覚情報あり)をわずかに上回った結果は、今回の検証に利用した25件の質問セットが適切な回答生成のためにデータソースに含まれる視覚情報を必要としないものであったことも影響したと推察される。
以上の考察から、本検証は、実務環境における複雑な要求に応えるためには、RAGアーキテクチャ全体の設計が性能を左右する重要な要素であることを実証した。
第2章の利用動向分析では、利用者の質問が単一の情報探索から、複数の文書を横断的に参照し統合する必要がある「複合的なクエリ」へと質的に高度化していることが明らかになった。この変化は、一度の検索で回答を生成する従来型のRAGアーキテクチャでは対応が困難であるという、新たな技術的課題を浮き彫りにした。本章では、この課題に対し、どのような技術的アプローチが有効であるかを比較検証によって実証することを目的とする。
利用者が直面する問題は、単一文書の参照のみでは解決せず、複数のマニュアルに分散した情報を横断的に調査したり、エラーメッセージとその発生状況を照合して原因を推論したりするなど、高度な情報統合能力を必要とするものが少なくない。この要求に応えるため、当社は従来のRAGアーキテクチャを問い直し、AIエージェントが質問を複数のサブクエリに分解し、自律的・再帰的に情報を探索・統合する、いわゆる「Agentic RAG」と呼ばれる仕組みを独自に実装した。本レポートで検証するAskDonaの最新バージョン(dona-rag-2.0 および dona-rag-2.5)は、この新しいアーキテクチャに基づいている。
AskDonaの2つの最新バージョンは、データソースの事前処理方法に違いがある。「dona-rag-2.0」は、OCRによる高精度な文字・表認識を特徴とする。一方、「dona-rag-2.5」は、dona-rag-2.0の機能に加え、文書内の図やグラフといった視覚情報の内容をテキスト化し、検索対象に含める機能を備えている。
本検証では、情報の正確性に加え、複数文書にまたがる横断的な調査や専門的な推論といった高度な要求に対し、AskDonaの最新バージョン(dona-rag-2.0 及び dona-rag-2.5)と主要なRAGがどの程度の性能を発揮できるかを評価する。具体的に広く利用されているクラウドプロバイダーのサービス(Microsoft社 Azure AI Search、Google社 Vertex AI Search、Amazon社 Amazon Bedrock)とオープンソースフレームワークはLangChainを用いてRAGシステムを構築した。
全システムには、PDF、CSV、HTML形式を含む「富岳」の専門文書239点(合計約16,000ページ以上)を同一のRAGのデータソースとして利用した。そして、「富岳」の運用に携わるR-CCSの専門家が、実際の問い合わせ傾向を反映して選抜した25問の「複合的な質問」を評価用の質問セットとして用いた。各システムが生成した回答の品質は、R-CCSの専門家による厳密な「人的評価」を通じて評価し、その回答精度を検証した。
以降のセクションでは、この検証の具体的な設計(2.1)、評価手法(2.2)、そしてその結果(2.3)について詳述する。
4.1 検証の設計と評価方法
本節では、比較検証の公正性と再現性を担保するために設定した各RAGシステムの構築条件について詳述する。本検証では広く利用されているクラウドプロバイダーのサービスが提供するRAGシステムとオープンソースフレームワークをAskDona(dona-rag-2.0 及び dona-rag-2.5)の比較対象として選定した。具体的には、Microsoft社のAzure AI Search、Google社のVertex AI Search、Amazon社のAmazon Bedrock、そしてオープンソースソフトウェア(Open Source Software、OSS) であるLangChainを用いて、4つのRAGシステムを構築した。
検証にあたり、AskDonaがRAGのデータソースとするPDF、 CSV、 HTML形式を含む「富岳」の専門文書239点(合計約16,000ページ以上)を全ての比較対象システムに同一のデータセットとして利用した。
RAGシステムの構築には、チャンク分割の手法、Embeddingモデルの選定、検索アルゴリズムのパラメータといった、調整可能な変数は多数存在する。これらの組み合わせは膨大であり、特定の条件下で性能を最大化するためのチューニングが可能である。
しかし、本検証の目的は特定のシステムを極限までチューニングすることではなく、異なる技術アプローチの基本的な性能を公正に比較することにある。そこで、各比較対象システムは、それぞれのプロバイダーが推奨する設定や広く認知されたベストプラクティスに基づき、標準的でありながら高い性能が期待できる状態へと最適化を行った。
各システムの性能を最大限に引き出すため、構築にあたってはAskDona(dona-rag-2.0 及び dona-rag-2.5)を除くシステムについて以下の共通方針を定めた。共通方針に基づき構築された各システムの概要と設定条件は表4.1の通りである。
同一データソースの利用: 全てのシステムで、全く同じ専門文書群をデータソースとして使用する。
高性能モデルの採用: 回答生成には各プラットフォームで利用可能な高性能な生成モデルを採用。Embeddingには高次元のモデルを優先的に採用する。
検索件数(Top-K)の統一: 回答生成の根拠として参照する文書チャンクの数を揃えるため、検索件数(Top-K)は全てのシステムで10件に統一する。
チャンク手法の標準化: 多くのクラウドプロバイダーが固定長のチャンク分割を標準としているため、本検証でも固定長チャンキングを基本とし、各プロバイダーの推奨設定またはデフォルト値に従う。
再現性の確保 (temperature設定): 回答の揺らぎをなくし、再現性を担保するため、生成モデルのtemperatureは原則として0に設定する。
最善なテキスト抽出手法の選択: OCR処理が適用可能な場合は必ず実行し、テキスト抽出の精度を高める。
指示プロンプトの統一: 各システムに与える指示プロンプト(システムプロンプト)は、条件を揃えるため全て同一のものを使用する。
ベクトルインデックスの作成: 検索効率と精度を高めるため、ベクトルデータのインデックスを必ず作成した。
表4.1:比較対象RAGシステムの構築条件詳細
RAGシステム | Microsoft社 Microsoft Azure(Azure AI Search) | Google社 Google Cloud (Vertex AI Search) | Amazon社 | LangChain (OSS) |
主要サービス | Azure AI Search, Azure OpenAI | Vertex AI Search | Bedrock KB, OpenSearch, S3 | FAISS (CPU), OpenAI API |
生成モデル | GPT-4o | Gemini 2.0 Flash | Claude Sonnet 4 | GPT-4o |
Embeddingモデル | text-embedding-3-large | text-embedding-004 | amazon.titan-embed-text-v2:0 | text-embedding-3-large |
ベクトル次元数 | 3072 | 768 | 1024 | 3072 |
チャンク手法 | サイズ: 2000文字 オーバーラップ: 500文字 | サイズ: 1000文字 オーバーラップ:100文字 | サイズ: 300トークン オーバーラップ: 20% | サイズ: 1000文字 オーバーラップ:200文字 |
検索手法 | ハイブリッド検索 | ベクトル検索 + キーワード検索 | ベクトル検索 | 近似近傍探索 (FAISS) |
OCR処理 | Azure AI Vision (Skillset) | Vertex AI Search (Built-in) | なし (S3からの直接取込), マルチモーダルモデルへの画像認識 | Tesseract (unstructured) |
4.2 評価用質問セットの選定
本節では、前節で構築した6つのRAGシステム(AskDona dona-rag-2.0、dona-rag-2.5 および比較対象4システム)の回答精度を測定するために用いた、評価用質問セットの選定基準について詳述する。
本検証で用いる質問セットは、情報の正確性に加え、複数文書にまたがる横断的な調査や専門的な推論といった高度な要求が求められる富岳サポートサイトの環境を例として、実際にAskDonaに送信された利用者質問(クエリ)の傾向を分析し、その結果に基づいて設計した。
特に、表4.2-1に記載される定義に沿った質問を25つの質問を厳選した。これらの質問は、検索された単一の情報を要約するだけでは回答できない質問や一般的なRAGシステムが構造的に回答生成を困難とする質問(複合的なクエリ)、およびユーザーによる入力間違いを含む質問である。
表4.2-1:評価用質問セットの定義
質問カテゴリ | 定義 |
情報統合性能を問う質問(複合的なクエリ) | 単一の情報源だけでは回答できず、複数の文書にまたがる情報を多角的な視点から横断的に探索・統合し、論理的に再構成する必要がある質問。 |
高精度な検索(リトリーバル)性能を問う質問 | 類似する情報やエラーコードが多数文書内に存在し、その中から最も関連性の高い情報を正確に特定する能力が求められる質問。 |
曖昧・不完全な入力への対応性能を問う質問 | 質問文に誤字脱字が含まれる場合や、質問の意図が不明確で、システム側が利用者の真の要求を推論・解釈する必要がある質問。 |
意味理解と類推性能を問う質問 | 質問で使われている言葉が、データソースとなる文書内に直接存在しない場合でも、意味的な類似性や文脈から関連情報を特定し、紐付ける能力が求められる質問。 |
情報の有無を正確に判断する性能を問う質問 | データソースに「存在する内容」と「存在しない内容」が混在している場合に、存在しない情報を正確に特定し、「その情報はない」と回答に含めることができるかを評価する質問。 |
本検証で用いる質問セットの内容は実際AskDonaに送信された質問を利用しているため、図4.2-2に参考情報として公開可能な質問例を公開する。図4.2-2の質問は、実際に富岳サポートサイトのAskDonaでよく受け付けるエラーメッセージに関する質問である。AskDonaの初期バージョン(dona-rag-1.0)は、ユーザーの質問に対して適切な回答を生成するものの、質問文に質問の背景や前提が不足している場合には、的確な回答が得られにくいという特性があった。一方、AskDona(dona-rag-2.0)は、ユーザーの質問意図を過去のチャット履歴から解釈してサブクエリ化、AIエージェントが自律的かつ再起的に情報を調査・取得したりすることで、より的確で網羅性の高い充実した回答生成を実現している。
図4.2-2:単一の情報を要約するだけでは回答できない質問例
4.3 本検証における評価アプローチと評価基準の選定
本節では、前節で厳選された25問の質問セットを評価するための評価手法について詳述する。
本検証の評価を決定するにあたり、既存のRAGシステム評価手法を検討した。近年、RAGシステムの性能を自動で評価する試みとして、いくつかのフレームワークが提案されている。例えば、生成された回答の忠実性(Faithfulness)や関連性(Relevance)等を定量化するRAGAs (Es et al., 2023) や、公開QAデータセットを用いてスコアを競うRAG-QA Arena (Lee et al., 2024)といった取り組みがある。これらの自動評価手法は、標準的なRAGプロセスの性能を迅速に把握する上で一定の有用性を持つ。
しかし、本検証では、専門家の知見に基づく人的評価が最も妥当なアプローチであると判断した。その理由として、まず評価対象である「AskDona」が、質問をサブクエリに分解したり、エージェントが自律的・再帰的に情報を探索したりする独自のアーキテクチャを持つ点があげられる。このような複雑な情報処理は、既存の自動評価フレームワークが前提とする単純なプロセスとは異なり、その性能を十分に評価しきれない可能性がある。さらに、本検証の目的でもある社会実装の促進のために必要な「実用性(Practical Utility / Helpfulness)」を専門家の視点から評価することが重要と考えた。この指標は、回答の納得感や問題解決への直接的な貢献度といった、現状の自動評価手法では測定が難しい側面を含む。これらの点を総合的に勘案し、今回の検証では専門家による人的評価を通じて、システムの有効性、特にその実用性や回答の質を深く測定するアプローチを採用した。この人的評価を実施するにあたり、客観性と信頼性を担保するため、以下の評価プロセスと評価基準を設計した。
◾️評価プロセスの設計
評価の客観性と信頼性を担保するため、厳格な評価プロセスを設計した。まず、評価は「富岳」の技術と運用に精通したR-CCSの専門家3名が担当した。評価対象としたのは、AskDona(dona-rag-2.0 標準モデル、dona-rag-2.5 視覚情報処理モデル)および、Microsoft Azure AI Search、Google Cloud Vertex AI Search、Amazon Bedrock、LangChain(OSS)で構築したRAGシステムの合計6つである。このうち、AskDonaを除く4つの比較対象システムは、第4.1節で詳述した構築条件に基づき用意された。
評価手順においては、評価バイアスを排除することを最優先とした。具体的には、どのシステムが生成した回答かを伏せた状態(ブラインド評価)で、各質問に対する6つの回答の順序をランダムに入れ替えて評価者に提示した。さらに、各評価者は独立して評価を行い、互いの結果を閲覧できない状態を確保することで、評価の独立性を担保した。
◾️評価基準の定義
評価には、前節の定義により選定された25問の質問セットを用いた。
各システムの回答に対し、以下の3つの評価指標をそれぞれ5段階でスコアリングした。評価指標は、RAGAsに代表されるRAG評価フレームワークの考え方を参考に、本検証に適当な評価項目を設定した。
正確性 (Accuracy / Factuality):
生成AIの基本的な信頼性に関わる最重要指標である。情報の正確性は利用者の信頼に直結するため、事実に基づいた回答を生成する能力を厳格に評価する。これは、RAGAsにおける Faithfulness(回答が文脈に忠実か)の概念を包含した。
網羅性 (Completeness / Comprehensiveness):
利用者の質問に対し、回答が必要な情報をどの程度抜け漏れなく含んでいるかを評価する。特に複合的な質問では、複数の情報源から関連情報を集め、適切な推論や要約をすることが求められる。これは、RAGAsにおける Contextual Recall(検索された文脈が正解を網羅しているか)と Answer Relevancy(回答が質問の全ての側面に適切に応えているか)の概念を包含した。
実用性 (Practical Utility / Helpfulness):
回答が単に正しいだけでなく、利用者の問題解決に実際に役立つかを総合的に評価する指標である。これには、RAGAsの Answer Relevancy(回答が質問に関連しているか)の観点に加え、専門家の視点から見た納得感、具体的なアクションへの貢献度、さらには専門用語の適切性や論理的整合性(ドメイン適合性)といった、より実践的な側面も含まれる。
これらの評価軸は、RAGシステム評価に関する研究で考慮される基本的な観点を網羅しつつ、本検証が重視する専門性と実用性を測るために調整されており、各システムの総合的な性能評価を行う上で妥当かつ十分なものであると判断した。
5段階のスコアリングについても評価指標の定義を以下の表4.3のように行った。
表4.3:評価指標の定義
評価指標 | 評価基準(5点) | 評価基準(3点) | 評価基準(1点) |
正確性 (Accuracy / Factuality) | 全ての事実が正確で、誤情報や幻覚(ハルシネーション)が一切ない。 | 一部に正確な情報も含まれるが、重要な誤情報や幻覚も散見される。 | 回答の大部分が不正確またはハルシネーション(幻覚)で構成されている。 |
網羅性 (Completeness / Comprehensiveness) | 必要な情報が完全に網羅され、全ての主張が参照元に明確に裏付けられている。 | 重要な情報の一部が欠落しているか、一部の主張の根拠が不明である。 | 質問の大部分に答えておらず、情報が著しく不足している。 |
実用性 (Practical Utility / Helpfulness) | 質問意図に完全に合致し、専門家にとって非常に納得感があり、問題解決に直接役立つ。 | 部分的には有用だが、意図から逸れる部分があるか、内容がやや分かりにくい。 | 質問意図を全く把握しておらず、ユーザーにとって全く有用ではない。 |
この評価設計により、各RAGシステムが持つ問題解決能力を、専門的かつ実践的な観点から評価することを目指した。表4.3の評価指標の定義に従い、任意のRAGシステムAとBから出力された回答の評価を行った例を図4.3に示す。システムAの回答は、参照元は、適切に取得してきているが、記載されている内容の具体性に欠けており結果的に実用的な回答として評価されない例である。それに対してシステムBは適切な参照元から具体的なジョブの実行スクリプトの提示や質問文からは判断できない想定されるうる複数の対処法の提示を行っているため正確性、網羅性、実用性含めて高い評価を受けるような例である。
図4.3:各システムから出力された回答の評価例
4.4 回答精度評価結果
前節で設計した評価プロセスに基づき、6つのRAGシステム(AskDona dona-rag-2.0、dona-rag-2.5 および比較対象4システム)に対して25問の「複合的な質問」セットを用いた人的評価を実施した。本節では、その評価結果を報告し、考察する。
スコアは、3名のR-CCS評価者による25問への5段階評価(1〜5点)を各指標(正確性、網羅性、実用性)ごとに集計し、満点を100ポイント(pt)として正規化したものである。
図4.4-1は、各システムについて3つの評価指標(正確性、網羅性、実用性)の平均スコアを比較したものである。評価の結果、比較対象とした4システムのスコアは50ポイント台から70ポイント台前半の範囲に分布し、その総合平均は約61ポイントであった。これに対し、AskDonaはdona-rag-2.0が83ポイント、dona-rag-2.5が82ポイントとなり、比較対象の平均を20ポイント以上上回る結果となった。
図4.4-1:「複合的なクエリ」を含む質問セットに対する各社RAGの獲得ポイント比較 (総合評価)
図4.4-2は、各システムについて3つの評価指標(正確性、網羅性、実用性)ごとのスコアを示したものである。AskDona(dona-rag-2.0)は、全ての比較対象を各指標で上回った。具体的には、主要なクラウドRAGサービスの一つであるAzure AI Search(正確性66pt、網羅性60pt、実用性58pt)に対して、正確性で18ポイント、網羅性で24ポイント、実用性で23ポイント上回った。比較対象の中で最も高いスコアであったAmazon Bedrock(正確性71pt、網羅性67pt、実用性63pt)に対しても、正確性で13ポイント、網羅性で17ポイント、実用性で18ポイント上回る結果となった。同様にLangChainやVertex AIに対しても、dona-rag-2.0が全ての指標で優位なスコアを記録した。
図4.4-2:「複合的なクエリ」を含む質問セットに対する各社RAGの獲得ポイント比較
今回の比較検証の結果、AskDonaは全ての評価指標において、比較対象とした4つのRAGシステムを上回るスコアを記録した。この結果から、いくつかの点が示唆される。
比較対象システムのスコアが最高でも70ポイント台前半に留まったのに対し、AskDonaはいずれのバージョンも80ポイント台のスコアを獲得した。この差は、最終的な回答品質が生成モデル(LLM)単体の性能だけでなく、RAGのアーキテクチャ全体に大きく依存することを示唆している。
この傾向は、比較対象内で最高スコアを記録したAmazon Bedrockの事例からも見て取れる。Bedrockは高性能なLLMを採用しているにもかかわらず、AskDonaはそれを全ての指標で上回った。これは、「複合的なクエリ」へ対応するためには、高性能なLLMを搭載するだけでなく、その能力を最大限に引き出すための高度なアーキテクチャ設計が不可欠であることを裏付けている。
なお、dona-rag-2.0(文字や表情報のみ)が、dona-rag-2.5(視覚情報あり)をわずかに上回った結果は、今回の検証に利用した25件の質問セットが適切な回答生成のためにデータソースに含まれる視覚情報を必要としないものであったことも影響したと推察される。
以上の考察から、本検証は、実務環境における複雑な要求に応えるためには、RAGアーキテクチャ全体の設計が性能を左右する重要な要素であることを実証した。

レポートリスト