開く
目次
第2章
理研「 富岳 」サポートサイトの 「生成AIチャット」及び「高度検索」の利用動向実績
理研「 富岳 」サポートサイトの 「生成AIチャット」及び「高度検索」の利用動向実績
本章では、スーパーコンピュータ「富岳」サポートサイトに導入された生成AIチャット「AskDona」と「高度検索」が、利用者の行動やサポート体制にどのような影響を与えたかを、定量的・定性的に分析し、その成果と現状を報告する。
本プロジェクトにおいてRAG技術が採用された背景として、LLMは主にウェブや書籍などの公開情報で学習されており、特定の組織が持つ非公開情報は知識として持っていないという前提がある。「富岳ウェブサイト」および「富岳サポートサイト」で提供されているマニュアルや利用手引書等の情報は一般公開されていないため、LLMの学習情報からは「富岳」に関する専門的な質問に適切に回答できない。また、「富岳ウェブサイト」および「富岳サポートサイト」は会員のみがアクセス可能なため、「ウェブ検索」機能等を搭載したLLMアプリケーションでも適切な回答はできない。そのため、一般的な情報を元にした回答を生成するか、根拠のない情報を生成する(ハルシネーション)リスクがある。
この課題を解決する技術の一つがRAGである。RAGとは、LLMが回答を生成する際、組織固有の文書などLLMが学習しておらずアクセス不可能なデータソースから関連情報をリアルタイムで検索し、その内容をLLMに参照させる技術である。これにより、組織固有の非公開情報に基づいた正確な回答の生成や、ハルシネーションのリスク低減が期待できる。
当社が開発した、独自のRAGソリューションを基盤とした生成AIチャット「AskDona」は、本プロジェクトへ参画するにあたり、R-CCSが定めた技術要件を満たすことを示す「導入前技術評価」が2024年5月に実施され、AskDonaの初期バージョン(dona-rag-1.0)が、R-CCSが定める技術要件(回答精度80%以上)に対し設定質問へ全問正解(回答精度100%)を達成し、大容量データから高い回答精度を実現する基本的なRAGの仕組みが評価されている。
2.1 AskDona初期バージョン(dona-rag-1.0)の技術概要
本節では、AskDonaを支える中核技術であるRAGアーキテクチャ、特に富岳サポートサイトへの導入時に採用された初期バージョン「dona-rag-1.0」の具体的な実装について詳述する。「導入前技術評価」が行われた2024年5月当時、RAGの実用的な検証例はまだ少なく、RAGデータソースから正しい回答を生成することが重要な課題であった。そのため、本プロジェクトでは一般的なRAGの構造を基礎としつつ、当社独自の技術を組み合わせて回答精度と品質を確保するアプローチを採用した。
一般的に、RAGシステムは大きく二つのプロセスから構成される。一つは、あらかじめ回答情報源とする文書(ファイル)から情報を取り出して検索可能なデータソースを構築する「事前処理」であり、もう一つは、利用者の質問に応じてデータソースから関連情報を検索し、LLMに渡して回答を生成させる「リアルタイム処理」である。「dona-rag-1.0」では、これらのプロセスを以下のように実装した。
まず「事前処理」において、データソースとなる多様な形式の文書から、単純なテキスト検出に留まらない高精度な情報抽出を行う。具体的には、OCR(光学文字認識)技術を基本とし、文書内の表情報を構造を保ったまま抽出するほか、数式や化学式のLaTeX形式で記述された専門的な内容も正確に認識して抽出する。
次に、抽出したテキスト情報をデータソースに格納するために分割する「チャンキング」を行うが、ここでは一般的な固定長の分割ではなく、文書の文脈を解析し「意味のあるまとまり」を単位として動的に分割する独自の手法を採用している。これにより、情報の分断を防ぎ、検索精度の向上が図られる。この当社の分割手法は、分割処理をLLMに委ねる際に懸念される情報の抜け漏れを原理的に発生させない利点も持つ。
続いて「メタデータ付与」を行う。富岳サポートサイトのように、数万ページに及ぶ多種多様なマニュアル群を扱う条件下では、この工程が極めて重要な意味を持つ。一般に、RAGシステムはデータソースとなる文書を追加すればするほど検索対象の空間が広がり、意味的に類似していても文脈的には無関係な情報(ノイズ)を検索してしまう可能性が高まるため、回答精度が低下するというトレードオフの関係が存在する。AskDonaは、この大規模データソース特有の課題を、メタデータ付与をはじめとする独自技術によって克服している。
具体的には、分割された各テキストチャンクに対し、ファイル名、ページ番号、章・節の見出しといった構造的な情報(メタデータ)を付与する。これにより、リアルタイム処理の検索プロセスにおいて、単に意味的に近いものを探すだけでなく、「特定のマニュアル内から」といった文脈に基づいた絞り込み検索が可能となる。このメタデータによるフィルタリングは、検索ノイズを効果的に排除し、最終的な回答の信頼性を大幅に高める。
このようなアプローチの有効性は、後にAnthropic社が公開した記事(2024年9月)でも「Contextual Retrieval」として提唱されており、大規模かつ多様な文書群を扱う上でのRAGの精度向上に有用な手法として認識されている。
その後、メタデータが付与されたテキストチャンクを「ベクトル化」する。ここでは、EmbeddingモデルとしてOpenAI社のtext-embedding-3-largeを採用し、当時利用可能な最大次元数である3072次元のベクトルへと変換した上で、データソースに保存する。
「リアルタイム処理」では、利用者から受け付けた質問を、事前処理で用いたものと同一のtext-embedding-3-largeモデルでベクトル化する。そして、その質問ベクトルを用いてデータソース内でコサイン類似度に基づいた検索(Retrieval)を行い、関連性が高いと判断された上位10件(Top-K=10)のテキスト情報を取得する。
最終的に、取得したテキスト情報と利用者の元の質問、そして回答の形式やトーンを指示するシステムプロンプトを組み合わせ、生成モデル(LLM)に渡して回答を生成させる。本実装では、国産LLM等の検討を重ねた結果、生成モデルとして当時最高水準の性能を有していたOpenAI社のGPT-4を採用した。回答の再現性と安定性を確保するため、生成されるテキストの「創造性」(ランダム性)を調整するパラメータであるtemperatureについて検証を行い、事実に基づいた回答を優先すべく値を0.2に設定した。この一連の仕組みにより、「dona-rag-1.0」は導入前の技術評価において高い評価を得た。
2.2 導入プロダクトとサポート体制の移行
本節では、生成AIチャット「AskDona」と「高度検索」が利用者にどのように活用され、その利用動向が時間とともにどう推移したかを、実際の利用データに基づき定量的に分析する。本プロジェクトで導入された生成AIチャット「AskDona」は、ユーザーからの質問に対し、「富岳」のマニュアルや利用手引書といった情報源から回答を生成する対話型のチャットボットとして、当社が独自に構築したRAGアーキテクチャに基づき、より正確で充実した回答を提供する。「高度検索」は、このRAG技術の検索(Retrieval)プロセスを応用した検索機能である。自然言語で入力された質問の意図を理解し、関連性の高い情報をページ単位やアンカーリンク(章・節)単位で直接提示する。AskDonaとは異なり、LLMによる文章生成プロセスを介さない点が特徴である。
富岳サポートサイトに導入した生成AIチャット「AskDona」と「高度検索」の導線イメージを図2.2に示す。
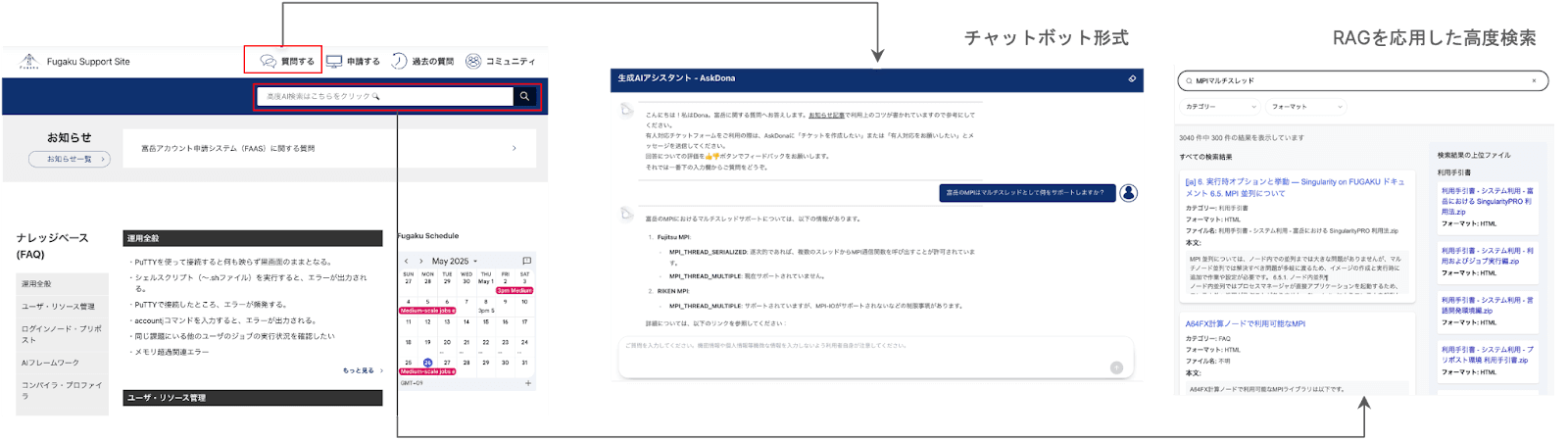
図2.2 富岳サポートサイトの生成AIチャット「AskDona」と「高度検索」の導線について
2024年7月に生成AIチャット「AskDona」と「高度検索」を導入した当初、利用者へのサポート提供方法として従来の問い合わせフォーム作成による有人対応とAskDonaによる自己解決方法(生成AIチャット対応)を選択できる「併用期間」を設けた。この併用期間を半年間続けてAskDonaの認知度が進んだ2025年2月に富岳サポートサイトの技術的な問い合わせ窓口を「AskDona」の生成AIチャットに一本化した。 これにより、利用者はまずAskDonaで解決を試み、そこで解決しない場合に問い合わせフォーム作成による有人問い合わせへ進む運用体制へと移行した。本章では、このサポート体制の段階的な移行を背景として、AskDonaおよび高度検索の利用動向がどのように変化したのかを、定量的なデータから明らかにする。
分析に用いる主要な指標は、セッション、回答済み質問数、およびセッションあたり平均メッセージ数の3つである。セッションは、期間内に新規で開始された利用者とAskDonaとの一連の対話の単位を指し、新規で何件新しいセッションが発生したかを確認する指標となる。回答済み質問数は、AskDonaが応答を返した質問の総数を示す。セッションあたりの平均メッセージ数は、1セッション内での利用者とAskDona間のやり取りの平均往復回数であり、対話の深さを示す指標となる。また、富岳サポートサイトには日本語(/jp)と英語(/en)のページが存在し、それぞれに対応するAskDonaと高度検索が導入されているが、本章で示すデータは両サイトの合算値である。
2.3 生成AIチャットの利用状況
本節では、生成AIチャット「AskDona」が利用者にどのように活用され、質問がどう推移したかを、定量的なデータから分析する。
◾️利用の定着
AskDona導入後の利用状況を分析した結果、本ツールが利用者にとって有効なサポート手段として定着していることが確認された。図2.3-1に示す通り、月間の平均利用実績は、質問数が676件、セッション数が123件であり、安定した利用が見られる。特に、2025年2月に有人サポートへの一次問い合わせ窓口をAskDonaに一本化して以降も、月間の平均質問数590件、セッション数104件と、安定した水準での利用が継続している。
また、対話の深さを示すセッションあたりの平均質問数は全体で5.6と、利用者が本ツールを単なる一問一答の検索エンジンとしてではなく、対話を通じて問題の深掘りや関連情報の取得を行うパートナーとして活用していることを示唆している。
図2.3-1の月次推移を見ると、2025年1月に回答済み質問数(1200件超)とセッションあたりの平均メッセージ数(約10往復)が一時的に突出している。この時期の利用者は主に「富岳」の利用経験が浅い初期ユーザーであった。これらの初期ユーザーによる活発な利用は、AskDonaが初心者の段階的な学習・対話ツールとして機能している可能性を示す一方で、自身の問題解決に向けた適切な問いを立てることが困難で試行錯誤を繰り返していた可能性を示している。
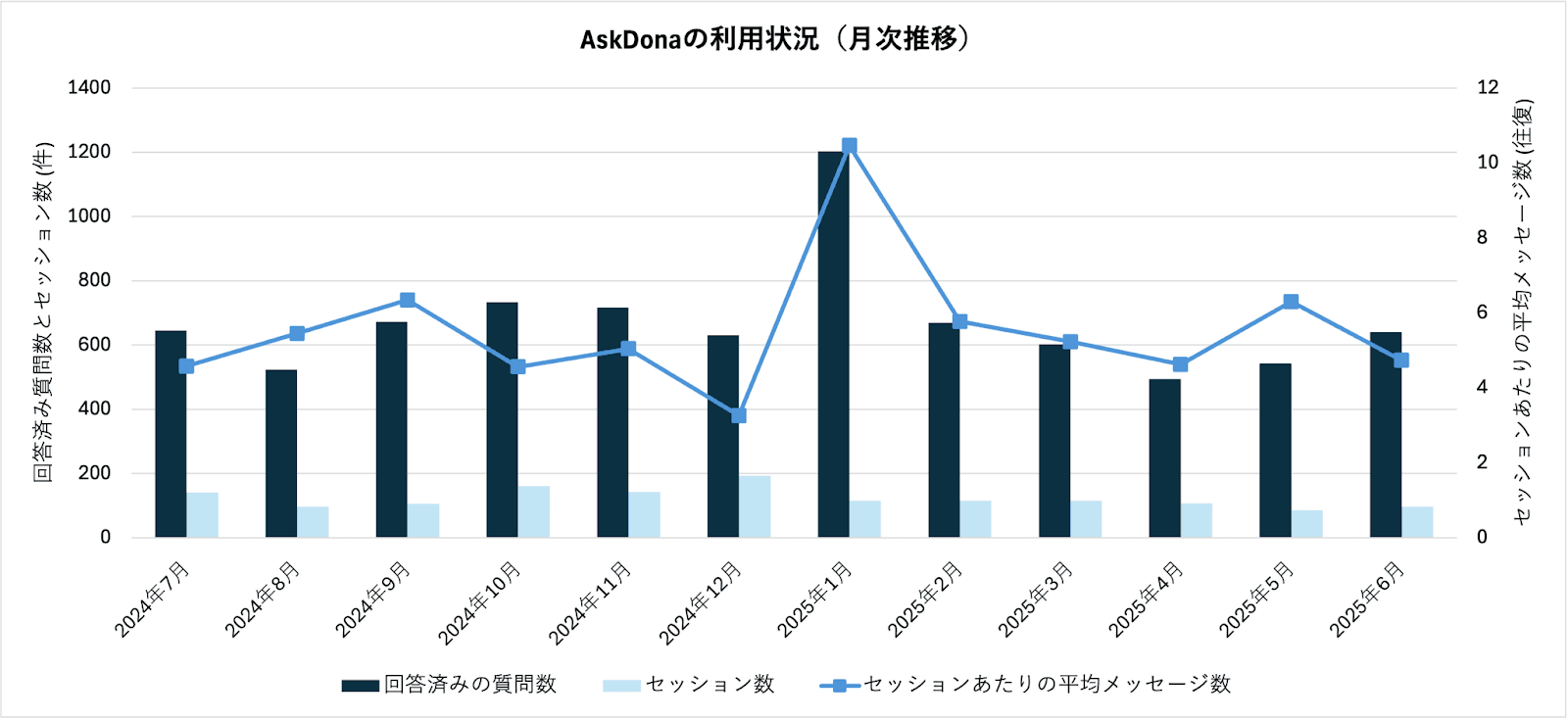
図2.3-1 AskDonaの利用状況(月次推移)
◾️品質の推移:不回答率の分析
AskDonaでは、ハルシネーションのリスクを低減するため、参照すべき情報がRAGデータソース内に見つからない場合、「申し訳ありません。関連する情報を見つけることができませんでした。」などの回答をする制御を行っている。この「不回答」の発生率は、RAGデータソースの情報の網羅性を測る重要な指標となる。
AskDonaには、この「不回答」となった質問と回答のペアを自動で特定する「RAGデータ不足分析機能」が標準で備わっている。 この機能を活用することで、管理者は「どのような質問に答えられていないのか」を即座に把握し、RAGデータソースの拡充に繋げることが可能である。
この不回答状況の推移を、図2.3-2に示す。実際に本プロジェクトでは、この機能によって特定された「富岳に関する基本情報」や「富岳の運用状況」といった、初期には不足していた情報をRAGデータソースに追加することで、情報の網羅性を改善した。その結果、不回答率は導入当初(2024年7月)の12%から、10月には7%まで大幅に低下し、RAGデータソースの情報の網羅性向上が確認された。
参考として、当社が提供するAskDonaの導入後3ヶ月間の平均不回答率は約15%である。これを一つの基準とすると、「富岳」サポートサイトにおける不回答率の推移は、極めて順調な改善を示していた。
一方で、一度7%まで低下した不回答率は、2025年1月には16%、4月には20%と再び上昇傾向に転じている。この傾向は、RAGシステムの品質が劣化したことを意味するのではなく、利用者が投じる質問の内容や質が変化し、より高度で複雑になっている可能性を強く示唆している。つまり、基本的な質問はAskDonaで解決できると認識した利用者が、より専門的で、多角的な視点から情報を参照し思考が必要な複合的な質問(クエリ)を投げかけるようになった結果、不回答率が一時的に上昇したと分析できる。この動向は、後述するクエリの複合化とも一致する。
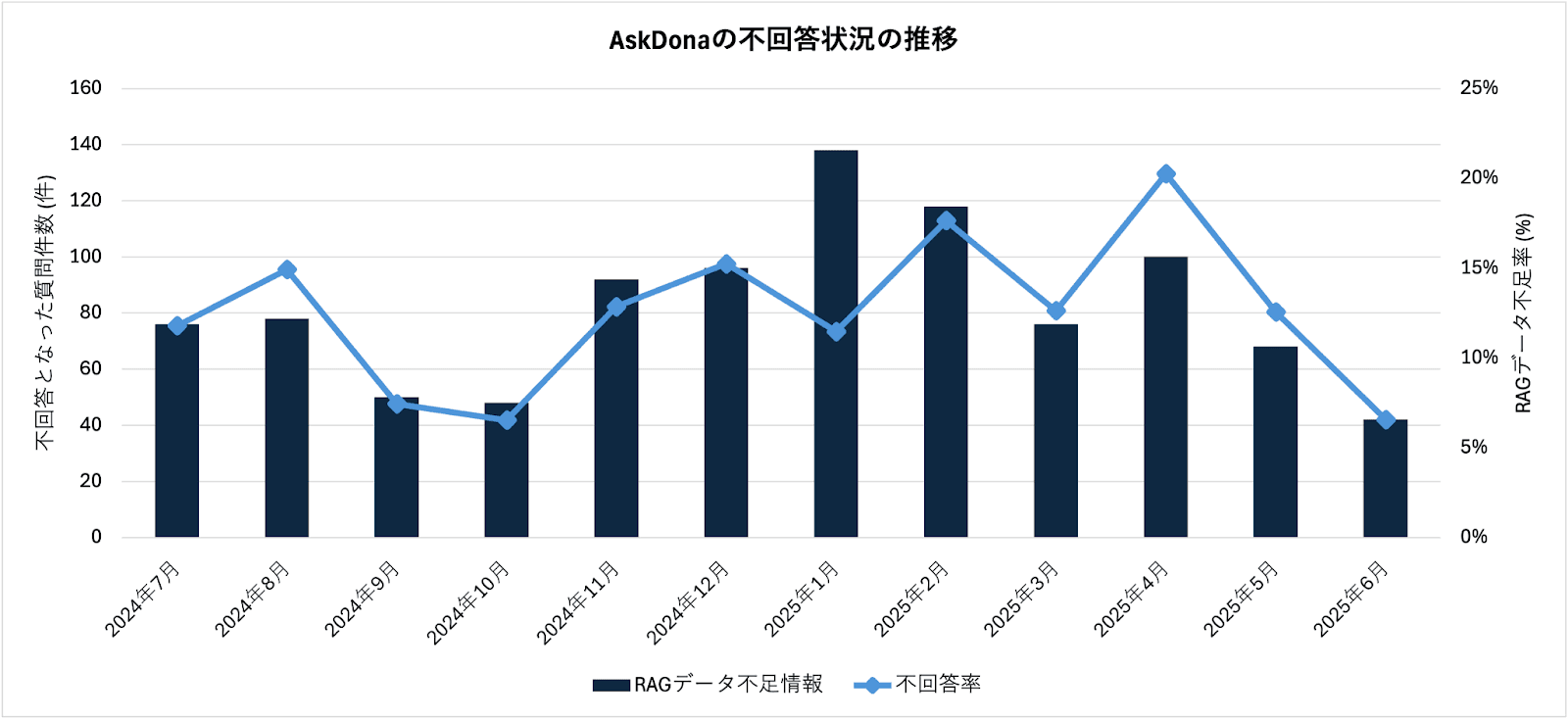
図2.3-2 AskDonaの不回答状況の推移
2.4 高度検索機能の利用状況
生成AIチャットと同時に導入された「高度検索」機能も、利用者の情報探索において重要な役割を担っている。この機能は、生成AIチャットとは異なり、ユーザーの検索内容に関連度の高い情報をページ単位で表示する(ファイル単位での表示も行う)。従来のキーワード検索と異なるのは、単なるキーワード検索ではなく利用者の質問の意図を理解した上で関連度の高い情報を提示する点にある。富岳サポートサイトに導入した「高度検索」のイメージを図2.4-1に示す。
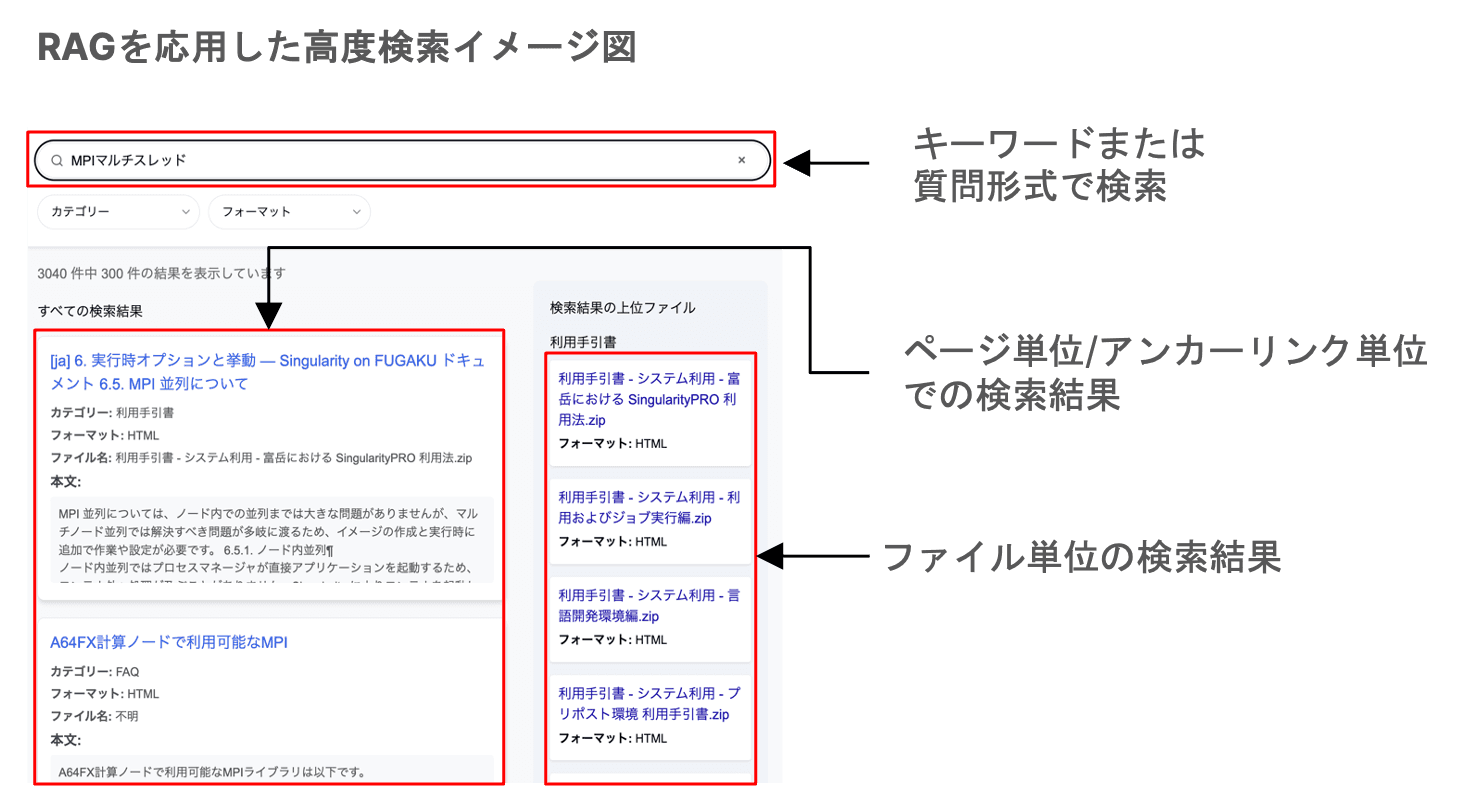
図2.4-1 富岳サポートサイトの「高度検索」イメージ画像
図2.4-2に示す通り、高度検索機能は導入初期から多くの利用を集め、2024年10月には月間2,602回とピークを記録した。その後、利用回数は緩やかな減少傾向を見せつつも、月平均で約1,457回(2024年7月~2025年6月)と安定した水準で利用が継続しており、サポートツールとして定着していることがわかる。
特に2024年後半から利用回数が減少傾向にあるが、利用者がAskDonaの対話機能に慣れ、単純な情報探索であっても高度検索ではなく生成AIチャットで完結させるケースが増えた可能性や、あるいはサイト全体の利用者の活動量が変動した可能性など、複数の要因が考えられる。またこの動向は、利用者が自身の目的や状況に応じて、2つのAskDonaと高度検索機能を使い分けていることも示唆していると考えられる。
「高度検索」が、このように生成AIチャットと並行して継続的に利用される背景には、その機能特性がある。生成AIチャットが対話を通じて複雑な問題解決を支援するのに対し、「高度検索」は、利用者が求める情報を文書内から迅速かつ正確に探し出す「情報探索」に特化したツールである。具体的には、検索クエリに対し、関連情報を単なるファイル単位だけでなく、ページ単位やアンカーリンク単位で直接提示し、その内容を検索結果内でプレビューできる。
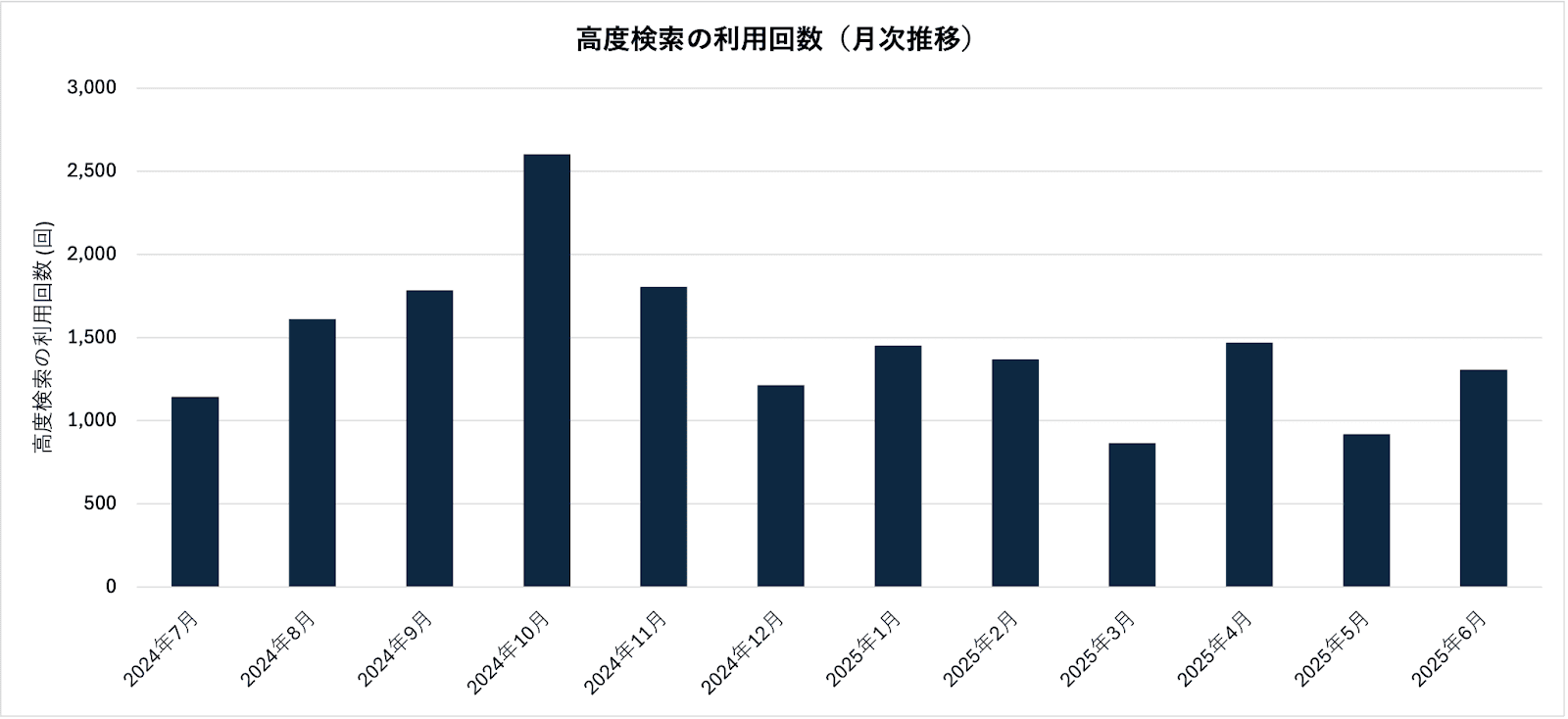
図2.4-2 高度検索の利用回数(月次推移)
2.5 AskDonaが受け付けるクエリ分類
AskDonaと高度検索の利用動向をさらに深く理解するため、本節では利用者が投じる質問(クエリ)の内容そのものに着目し、その質的な変化を分析する。分析にあたっては、クエリを「目的」と「構造的な複雑さ」という2つの軸で評価した。
まず、クエリの「目的」を特定の知識を求める「情報探索(Know)」と、具体的な解決策を求める「方法探索(How-Do)」に分類した。導入初期(2024年7月)と運用が定着した時期(2025年5月)のクエリ構成を比較したものが、図2.5-1である。
図が示す通り、導入初期には全体の44%を占めていた「情報探索」クエリは、2025年5月には26%へと減少した。一方で、「方法探索」クエリは初期の21%から48%へと倍増している。この傾向は、利用者がAIチャットを単なる「検索エンジン」から、より高度なタスクを依頼する「思考」へと、その役割認識を変化させていることを示唆する。
このクエリ目的の変化は、前節で見た「高度検索」の利用減少傾向の一因とも考えられる。つまり、利用者の関心が単純な情報探索から、より複雑な方法探索へと移るにつれて、情報探索に特化した「高度検索」の利用機会が相対的に減少した可能性がある。
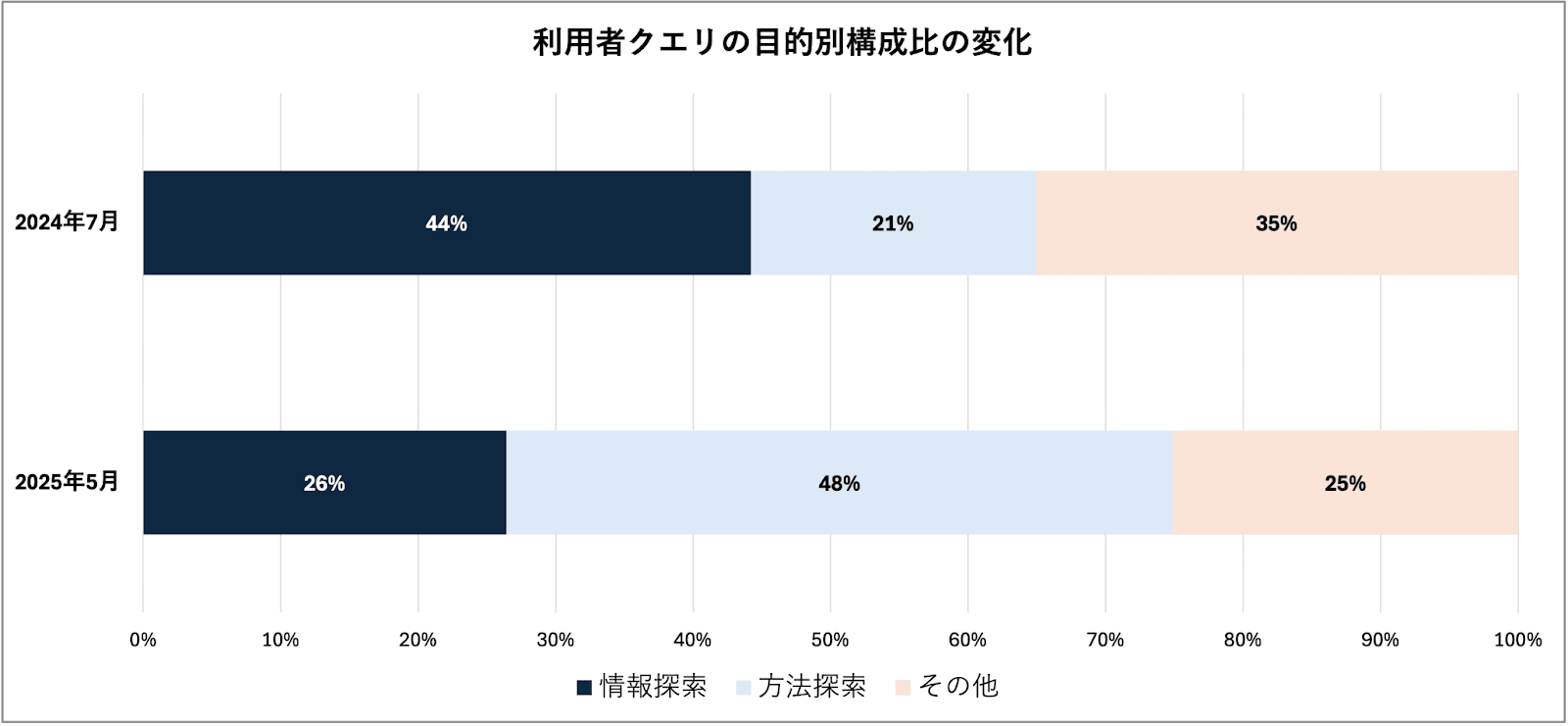
図2.5-1 利用者クエリの目的別構成比の変化(2024年7月 と 2025年5月)
次に、クエリの構造的な複雑さに着目する。ここでは、情報源を参照するだけでは回答できず、複数の文書にまたがる情報を段階的に調査し、多角的な視点から統合しなければ適切な答えを導き出せない問いを「複合的なクエリ」と定義した。図2.5-2は、全質問に占める「複合的なクエリ」の割合の推移を示している。
図が示す通り、「複合的なクエリ」の割合は、導入初期の2.3%から約10ヶ月後には10.0%へと、約4.3倍に増加した(7.7ポイントの上昇)。この結果は、クエリの目的が変化しただけでなく、個々の質問の難易度そのものが上昇していることを裏付けるものである。
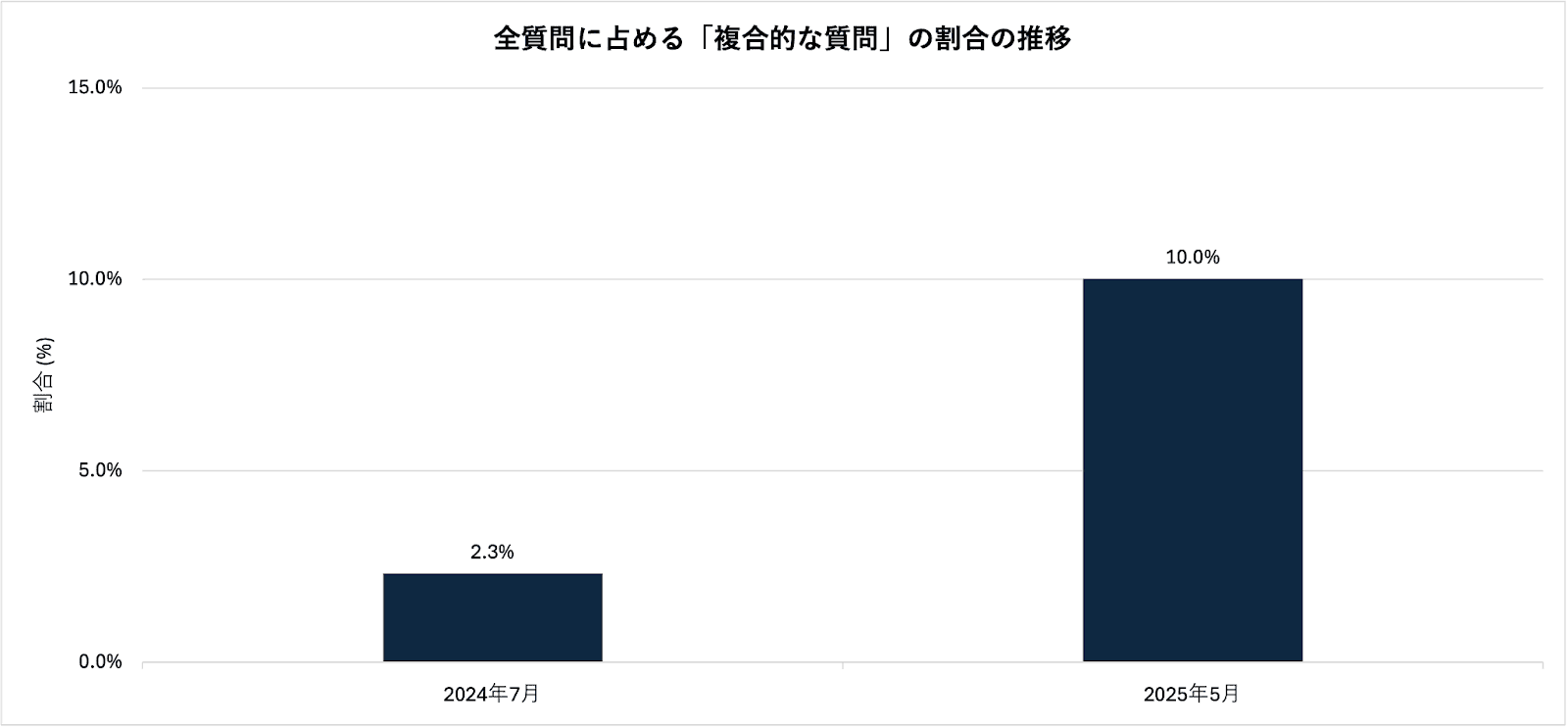
図2.5-2 全質問に占める「複合的な質問」の割合の推移
このようなクエリの複合化は、利用者側の行動変容を強く示唆している。その背景には、いくつかの要因が複合的に絡み合っていると考えられる。
要因の一つとして、利用者がAskDonaの能力を認識し、その活用方法が深化していったことが挙げられる。初期の性能を試す段階から、実務課題を解決するツールへと移行する中で、単一の事実確認に留まらず「代替案の比較」や「判断根拠の列挙」といった、より多面的な回答を求める質問が増加した。
さらに、2025年2月に行われたサポート体制の変更も、この傾向を加速させた。有人サポートへの一次窓口がAskDonaに一本化されたことで、利用者はこれまで有人担当者に依頼していたような、背景や状況を詳細に記述した質問をAskDonaにも投げかけるようになった。
これにより、一つの質問文に複数の意図や制約が混在するケースが増加したと考えられる。
以上の考察から、「複合的なクエリ」の増加が示唆するのは、質問の専門性が高まったというよりも、利用者がAskDonaに求める「根拠の網羅性」と「視点の多様性」が高まったという質的な変化である。
本プロジェクトで定義する「複合的なクエリ」は、従来型のRAG(Retrieval-Augmented Generation)が採用する単発的な検索プロセスでは十分な情報を集めきれない問いを指している。これは、システムの応答性能に対する利用者の要求水準が、より高度な情報探索・統合能力を前提とするフェーズに入ったことを示している。
この利用者の要求の高度化は、dona-rag-1.0が採用するような、従来型のRAGアーキテクチャが持つ構造的な限界を浮き彫りにした。従来型RAGは、利用者の質問を一度だけベクトル化し、関連文書を検索して回答を生成する「単一ステップ検索-生成方式 (single-shot retrieval-generation) 」を基本とする。このアプローチは、情報のカバレッジが単一の検索結果に限定されるため、「複合的なクエリ」が求める多角的な情報収集には原理的に対応が困難であった。また、検索結果を評価し、不足している情報を自律的に再検索するような「反復的リトリーバル推論 (iterative retrieval-augmented reasoning)」のメカニズムも持たないため、一度の検索で十分な情報が得られなければ、質の高い回答を生成することはできなかった。
利用者の要求に応え続けるためには、RAGアーキテクチャそのものを進化させる必要がある。理想的な次世代のRAGは、単なる検索と生成の組み合わせではなく、より高度な思考プロセスを内包するべきである。具体的には、まず利用者の質問に含まれる複数の意図や視点を正確に解析し、解決すべきサブタスクへと分解する「質問意図解析」。次に、分解されたタスクに基づき、複数のAIエージェントが自律的かつ再帰的に情報収集、書き換え、評価を繰り返す「情報探索とフィードバック」のループ。そして、探索プロセス全体を記憶・評価し、次に何を探すべきかを動的に判断する「エージェント統合管理」。このような、階層的かつ動的なアーキテクチャこそが、「複合的なクエリ」に対する本質的な解決策となる。
当社は、この理想的なアーキテクチャを具現化すべく、AskDonaの次期バージョンとしてdona-rag-2.0およびdona-rag-2.5を構築した。続く第3章では、dona-rag-1.0の導入がサポート業務に与えた影響を分析し、第4章において、この次世代アーキテクチャが「複合的なクエリ」に対してどれほどの性能向上を実現したのかを、主要なRAGサービスとの比較検証を通じて定量的に実証する。
2.6 本章の結論
本章では、AskDonaと高度検索の導入後の利用動向を定量・定性的に分析した。その結果、以下の点が明らかになった。
第一に、AskDonaは利用者に有効なサポート手段として定着した。 月間の平均質問数・セッション数は安定した水準を維持し、1セッションあたりの平均質問数も約5.7件と、利用者がAskDonaを対話的に活用していることが示された。特に、利用経験の浅いユーザーほど対話数が多くなる傾向が見られ、学習・試行錯誤のツールとしても機能している可能性が示唆された。
第二に、利用の定着に伴い、利用者の要求はより高度化・複合化した。 利用者の質問目的は、単純な「情報探索」から具体的な「方法探索」へとシフトした。さらに、運用期間の経過と共に、複数の文書を横断的に調査・統合する必要がある「複合的なクエリ」の割合は約4.3倍に増加した。これは、利用者がシステムの能力を認識し、より困難な課題解決をAIに委ねるようになったこと、また、サポート窓口の一本化により、従来は有人担当者に投げていた詳細な質問がAskDonaに向けられるようになったことを示唆する。
第三に、クエリの複合化は、従来型のRAGシステムが共通して抱える構造的な限界を浮き彫りにした。 AskDona(dona-rag-1.0)において、クエリが高度化・複合化するにつれて不回答率が再び上昇した事実は、この課題を象徴している。これは特定のシステムの品質劣化を意味するのではなく、単発的な検索プロセスに依存する標準的なアーキテクチャでは、利用者が求める多角的な情報探索・統合に応えきれないという、RAG技術の一般的な課題が顕在化した結果である。
以上の分析から、実務環境で役立つRAGシステムを構築・運用するためには、基本的な検索・生成能力だけでは不十分であることが結論づけられる。利用者の習熟度や要求レベルは常に変化・向上するため、利用者の意図を深く解釈し、自律的に情報を探索・統合する高度なRAGアーキテクチャへの継続的なアップデートが不可欠であることを示唆した。
AskDonaの次期バージョン(dona-rag-2.0およびdona-rag-2.5)は、まさにこの課題に応えるために設計されたものであり、その回答精度の検証は第4章で詳述する。今後は、この次世代アーキテクチャを富岳サポートサイトへ適用し、さらに高度な利用者サポートを実現するツールとして成長させていく予定である。
本章では、スーパーコンピュータ「富岳」サポートサイトに導入された生成AIチャット「AskDona」と「高度検索」が、利用者の行動やサポート体制にどのような影響を与えたかを、定量的・定性的に分析し、その成果と現状を報告する。
本プロジェクトにおいてRAG技術が採用された背景として、LLMは主にウェブや書籍などの公開情報で学習されており、特定の組織が持つ非公開情報は知識として持っていないという前提がある。「富岳ウェブサイト」および「富岳サポートサイト」で提供されているマニュアルや利用手引書等の情報は一般公開されていないため、LLMの学習情報からは「富岳」に関する専門的な質問に適切に回答できない。また、「富岳ウェブサイト」および「富岳サポートサイト」は会員のみがアクセス可能なため、「ウェブ検索」機能等を搭載したLLMアプリケーションでも適切な回答はできない。そのため、一般的な情報を元にした回答を生成するか、根拠のない情報を生成する(ハルシネーション)リスクがある。
この課題を解決する技術の一つがRAGである。RAGとは、LLMが回答を生成する際、組織固有の文書などLLMが学習しておらずアクセス不可能なデータソースから関連情報をリアルタイムで検索し、その内容をLLMに参照させる技術である。これにより、組織固有の非公開情報に基づいた正確な回答の生成や、ハルシネーションのリスク低減が期待できる。
当社が開発した、独自のRAGソリューションを基盤とした生成AIチャット「AskDona」は、本プロジェクトへ参画するにあたり、R-CCSが定めた技術要件を満たすことを示す「導入前技術評価」が2024年5月に実施され、AskDonaの初期バージョン(dona-rag-1.0)が、R-CCSが定める技術要件(回答精度80%以上)に対し設定質問へ全問正解(回答精度100%)を達成し、大容量データから高い回答精度を実現する基本的なRAGの仕組みが評価されている。
2.1 AskDona初期バージョン(dona-rag-1.0)の技術概要
本節では、AskDonaを支える中核技術であるRAGアーキテクチャ、特に富岳サポートサイトへの導入時に採用された初期バージョン「dona-rag-1.0」の具体的な実装について詳述する。「導入前技術評価」が行われた2024年5月当時、RAGの実用的な検証例はまだ少なく、RAGデータソースから正しい回答を生成することが重要な課題であった。そのため、本プロジェクトでは一般的なRAGの構造を基礎としつつ、当社独自の技術を組み合わせて回答精度と品質を確保するアプローチを採用した。
一般的に、RAGシステムは大きく二つのプロセスから構成される。一つは、あらかじめ回答情報源とする文書(ファイル)から情報を取り出して検索可能なデータソースを構築する「事前処理」であり、もう一つは、利用者の質問に応じてデータソースから関連情報を検索し、LLMに渡して回答を生成させる「リアルタイム処理」である。「dona-rag-1.0」では、これらのプロセスを以下のように実装した。
まず「事前処理」において、データソースとなる多様な形式の文書から、単純なテキスト検出に留まらない高精度な情報抽出を行う。具体的には、OCR(光学文字認識)技術を基本とし、文書内の表情報を構造を保ったまま抽出するほか、数式や化学式のLaTeX形式で記述された専門的な内容も正確に認識して抽出する。
次に、抽出したテキスト情報をデータソースに格納するために分割する「チャンキング」を行うが、ここでは一般的な固定長の分割ではなく、文書の文脈を解析し「意味のあるまとまり」を単位として動的に分割する独自の手法を採用している。これにより、情報の分断を防ぎ、検索精度の向上が図られる。この当社の分割手法は、分割処理をLLMに委ねる際に懸念される情報の抜け漏れを原理的に発生させない利点も持つ。
続いて「メタデータ付与」を行う。富岳サポートサイトのように、数万ページに及ぶ多種多様なマニュアル群を扱う条件下では、この工程が極めて重要な意味を持つ。一般に、RAGシステムはデータソースとなる文書を追加すればするほど検索対象の空間が広がり、意味的に類似していても文脈的には無関係な情報(ノイズ)を検索してしまう可能性が高まるため、回答精度が低下するというトレードオフの関係が存在する。AskDonaは、この大規模データソース特有の課題を、メタデータ付与をはじめとする独自技術によって克服している。
具体的には、分割された各テキストチャンクに対し、ファイル名、ページ番号、章・節の見出しといった構造的な情報(メタデータ)を付与する。これにより、リアルタイム処理の検索プロセスにおいて、単に意味的に近いものを探すだけでなく、「特定のマニュアル内から」といった文脈に基づいた絞り込み検索が可能となる。このメタデータによるフィルタリングは、検索ノイズを効果的に排除し、最終的な回答の信頼性を大幅に高める。
このようなアプローチの有効性は、後にAnthropic社が公開した記事(2024年9月)でも「Contextual Retrieval」として提唱されており、大規模かつ多様な文書群を扱う上でのRAGの精度向上に有用な手法として認識されている。
その後、メタデータが付与されたテキストチャンクを「ベクトル化」する。ここでは、EmbeddingモデルとしてOpenAI社のtext-embedding-3-largeを採用し、当時利用可能な最大次元数である3072次元のベクトルへと変換した上で、データソースに保存する。
「リアルタイム処理」では、利用者から受け付けた質問を、事前処理で用いたものと同一のtext-embedding-3-largeモデルでベクトル化する。そして、その質問ベクトルを用いてデータソース内でコサイン類似度に基づいた検索(Retrieval)を行い、関連性が高いと判断された上位10件(Top-K=10)のテキスト情報を取得する。
最終的に、取得したテキスト情報と利用者の元の質問、そして回答の形式やトーンを指示するシステムプロンプトを組み合わせ、生成モデル(LLM)に渡して回答を生成させる。本実装では、国産LLM等の検討を重ねた結果、生成モデルとして当時最高水準の性能を有していたOpenAI社のGPT-4を採用した。回答の再現性と安定性を確保するため、生成されるテキストの「創造性」(ランダム性)を調整するパラメータであるtemperatureについて検証を行い、事実に基づいた回答を優先すべく値を0.2に設定した。この一連の仕組みにより、「dona-rag-1.0」は導入前の技術評価において高い評価を得た。
2.2 導入プロダクトとサポート体制の移行
本節では、生成AIチャット「AskDona」と「高度検索」が利用者にどのように活用され、その利用動向が時間とともにどう推移したかを、実際の利用データに基づき定量的に分析する。本プロジェクトで導入された生成AIチャット「AskDona」は、ユーザーからの質問に対し、「富岳」のマニュアルや利用手引書といった情報源から回答を生成する対話型のチャットボットとして、当社が独自に構築したRAGアーキテクチャに基づき、より正確で充実した回答を提供する。「高度検索」は、このRAG技術の検索(Retrieval)プロセスを応用した検索機能である。自然言語で入力された質問の意図を理解し、関連性の高い情報をページ単位やアンカーリンク(章・節)単位で直接提示する。AskDonaとは異なり、LLMによる文章生成プロセスを介さない点が特徴である。
富岳サポートサイトに導入した生成AIチャット「AskDona」と「高度検索」の導線イメージを図2.2に示す。
図2.2 富岳サポートサイトの生成AIチャット「AskDona」と「高度検索」の導線について
2024年7月に生成AIチャット「AskDona」と「高度検索」を導入した当初、利用者へのサポート提供方法として従来の問い合わせフォーム作成による有人対応とAskDonaによる自己解決方法(生成AIチャット対応)を選択できる「併用期間」を設けた。この併用期間を半年間続けてAskDonaの認知度が進んだ2025年2月に富岳サポートサイトの技術的な問い合わせ窓口を「AskDona」の生成AIチャットに一本化した。 これにより、利用者はまずAskDonaで解決を試み、そこで解決しない場合に問い合わせフォーム作成による有人問い合わせへ進む運用体制へと移行した。本章では、このサポート体制の段階的な移行を背景として、AskDonaおよび高度検索の利用動向がどのように変化したのかを、定量的なデータから明らかにする。
分析に用いる主要な指標は、セッション、回答済み質問数、およびセッションあたり平均メッセージ数の3つである。セッションは、期間内に新規で開始された利用者とAskDonaとの一連の対話の単位を指し、新規で何件新しいセッションが発生したかを確認する指標となる。回答済み質問数は、AskDonaが応答を返した質問の総数を示す。セッションあたりの平均メッセージ数は、1セッション内での利用者とAskDona間のやり取りの平均往復回数であり、対話の深さを示す指標となる。また、富岳サポートサイトには日本語(/jp)と英語(/en)のページが存在し、それぞれに対応するAskDonaと高度検索が導入されているが、本章で示すデータは両サイトの合算値である。
2.3 生成AIチャットの利用状況
本節では、生成AIチャット「AskDona」が利用者にどのように活用され、質問がどう推移したかを、定量的なデータから分析する。
◾️利用の定着
AskDona導入後の利用状況を分析した結果、本ツールが利用者にとって有効なサポート手段として定着していることが確認された。図2.3-1に示す通り、月間の平均利用実績は、質問数が676件、セッション数が123件であり、安定した利用が見られる。特に、2025年2月に有人サポートへの一次問い合わせ窓口をAskDonaに一本化して以降も、月間の平均質問数590件、セッション数104件と、安定した水準での利用が継続している。
また、対話の深さを示すセッションあたりの平均質問数は全体で5.6と、利用者が本ツールを単なる一問一答の検索エンジンとしてではなく、対話を通じて問題の深掘りや関連情報の取得を行うパートナーとして活用していることを示唆している。
図2.3-1の月次推移を見ると、2025年1月に回答済み質問数(1200件超)とセッションあたりの平均メッセージ数(約10往復)が一時的に突出している。この時期の利用者は主に「富岳」の利用経験が浅い初期ユーザーであった。これらの初期ユーザーによる活発な利用は、AskDonaが初心者の段階的な学習・対話ツールとして機能している可能性を示す一方で、自身の問題解決に向けた適切な問いを立てることが困難で試行錯誤を繰り返していた可能性を示している。
図2.3-1 AskDonaの利用状況(月次推移)
◾️品質の推移:不回答率の分析
AskDonaでは、ハルシネーションのリスクを低減するため、参照すべき情報がRAGデータソース内に見つからない場合、「申し訳ありません。関連する情報を見つけることができませんでした。」などの回答をする制御を行っている。この「不回答」の発生率は、RAGデータソースの情報の網羅性を測る重要な指標となる。
AskDonaには、この「不回答」となった質問と回答のペアを自動で特定する「RAGデータ不足分析機能」が標準で備わっている。 この機能を活用することで、管理者は「どのような質問に答えられていないのか」を即座に把握し、RAGデータソースの拡充に繋げることが可能である。
この不回答状況の推移を、図2.3-2に示す。実際に本プロジェクトでは、この機能によって特定された「富岳に関する基本情報」や「富岳の運用状況」といった、初期には不足していた情報をRAGデータソースに追加することで、情報の網羅性を改善した。その結果、不回答率は導入当初(2024年7月)の12%から、10月には7%まで大幅に低下し、RAGデータソースの情報の網羅性向上が確認された。
参考として、当社が提供するAskDonaの導入後3ヶ月間の平均不回答率は約15%である。これを一つの基準とすると、「富岳」サポートサイトにおける不回答率の推移は、極めて順調な改善を示していた。
一方で、一度7%まで低下した不回答率は、2025年1月には16%、4月には20%と再び上昇傾向に転じている。この傾向は、RAGシステムの品質が劣化したことを意味するのではなく、利用者が投じる質問の内容や質が変化し、より高度で複雑になっている可能性を強く示唆している。つまり、基本的な質問はAskDonaで解決できると認識した利用者が、より専門的で、多角的な視点から情報を参照し思考が必要な複合的な質問(クエリ)を投げかけるようになった結果、不回答率が一時的に上昇したと分析できる。この動向は、後述するクエリの複合化とも一致する。
図2.3-2 AskDonaの不回答状況の推移
2.4 高度検索機能の利用状況
生成AIチャットと同時に導入された「高度検索」機能も、利用者の情報探索において重要な役割を担っている。この機能は、生成AIチャットとは異なり、ユーザーの検索内容に関連度の高い情報をページ単位で表示する(ファイル単位での表示も行う)。従来のキーワード検索と異なるのは、単なるキーワード検索ではなく利用者の質問の意図を理解した上で関連度の高い情報を提示する点にある。富岳サポートサイトに導入した「高度検索」のイメージを図2.4-1に示す。
図2.4-1 富岳サポートサイトの「高度検索」イメージ画像
図2.4-2に示す通り、高度検索機能は導入初期から多くの利用を集め、2024年10月には月間2,602回とピークを記録した。その後、利用回数は緩やかな減少傾向を見せつつも、月平均で約1,457回(2024年7月~2025年6月)と安定した水準で利用が継続しており、サポートツールとして定着していることがわかる。
特に2024年後半から利用回数が減少傾向にあるが、利用者がAskDonaの対話機能に慣れ、単純な情報探索であっても高度検索ではなく生成AIチャットで完結させるケースが増えた可能性や、あるいはサイト全体の利用者の活動量が変動した可能性など、複数の要因が考えられる。またこの動向は、利用者が自身の目的や状況に応じて、2つのAskDonaと高度検索機能を使い分けていることも示唆していると考えられる。
「高度検索」が、このように生成AIチャットと並行して継続的に利用される背景には、その機能特性がある。生成AIチャットが対話を通じて複雑な問題解決を支援するのに対し、「高度検索」は、利用者が求める情報を文書内から迅速かつ正確に探し出す「情報探索」に特化したツールである。具体的には、検索クエリに対し、関連情報を単なるファイル単位だけでなく、ページ単位やアンカーリンク単位で直接提示し、その内容を検索結果内でプレビューできる。
図2.4-2 高度検索の利用回数(月次推移)
2.5 AskDonaが受け付けるクエリ分類
AskDonaと高度検索の利用動向をさらに深く理解するため、本節では利用者が投じる質問(クエリ)の内容そのものに着目し、その質的な変化を分析する。分析にあたっては、クエリを「目的」と「構造的な複雑さ」という2つの軸で評価した。
まず、クエリの「目的」を特定の知識を求める「情報探索(Know)」と、具体的な解決策を求める「方法探索(How-Do)」に分類した。導入初期(2024年7月)と運用が定着した時期(2025年5月)のクエリ構成を比較したものが、図2.5-1である。
図が示す通り、導入初期には全体の44%を占めていた「情報探索」クエリは、2025年5月には26%へと減少した。一方で、「方法探索」クエリは初期の21%から48%へと倍増している。この傾向は、利用者がAIチャットを単なる「検索エンジン」から、より高度なタスクを依頼する「思考」へと、その役割認識を変化させていることを示唆する。
このクエリ目的の変化は、前節で見た「高度検索」の利用減少傾向の一因とも考えられる。つまり、利用者の関心が単純な情報探索から、より複雑な方法探索へと移るにつれて、情報探索に特化した「高度検索」の利用機会が相対的に減少した可能性がある。
図2.5-1 利用者クエリの目的別構成比の変化(2024年7月 と 2025年5月)
次に、クエリの構造的な複雑さに着目する。ここでは、情報源を参照するだけでは回答できず、複数の文書にまたがる情報を段階的に調査し、多角的な視点から統合しなければ適切な答えを導き出せない問いを「複合的なクエリ」と定義した。図2.5-2は、全質問に占める「複合的なクエリ」の割合の推移を示している。
図が示す通り、「複合的なクエリ」の割合は、導入初期の2.3%から約10ヶ月後には10.0%へと、約4.3倍に増加した(7.7ポイントの上昇)。この結果は、クエリの目的が変化しただけでなく、個々の質問の難易度そのものが上昇していることを裏付けるものである。
図2.5-2 全質問に占める「複合的な質問」の割合の推移
このようなクエリの複合化は、利用者側の行動変容を強く示唆している。その背景には、いくつかの要因が複合的に絡み合っていると考えられる。
要因の一つとして、利用者がAskDonaの能力を認識し、その活用方法が深化していったことが挙げられる。初期の性能を試す段階から、実務課題を解決するツールへと移行する中で、単一の事実確認に留まらず「代替案の比較」や「判断根拠の列挙」といった、より多面的な回答を求める質問が増加した。
さらに、2025年2月に行われたサポート体制の変更も、この傾向を加速させた。有人サポートへの一次窓口がAskDonaに一本化されたことで、利用者はこれまで有人担当者に依頼していたような、背景や状況を詳細に記述した質問をAskDonaにも投げかけるようになった。
これにより、一つの質問文に複数の意図や制約が混在するケースが増加したと考えられる。
以上の考察から、「複合的なクエリ」の増加が示唆するのは、質問の専門性が高まったというよりも、利用者がAskDonaに求める「根拠の網羅性」と「視点の多様性」が高まったという質的な変化である。
本プロジェクトで定義する「複合的なクエリ」は、従来型のRAG(Retrieval-Augmented Generation)が採用する単発的な検索プロセスでは十分な情報を集めきれない問いを指している。これは、システムの応答性能に対する利用者の要求水準が、より高度な情報探索・統合能力を前提とするフェーズに入ったことを示している。
この利用者の要求の高度化は、dona-rag-1.0が採用するような、従来型のRAGアーキテクチャが持つ構造的な限界を浮き彫りにした。従来型RAGは、利用者の質問を一度だけベクトル化し、関連文書を検索して回答を生成する「単一ステップ検索-生成方式 (single-shot retrieval-generation) 」を基本とする。このアプローチは、情報のカバレッジが単一の検索結果に限定されるため、「複合的なクエリ」が求める多角的な情報収集には原理的に対応が困難であった。また、検索結果を評価し、不足している情報を自律的に再検索するような「反復的リトリーバル推論 (iterative retrieval-augmented reasoning)」のメカニズムも持たないため、一度の検索で十分な情報が得られなければ、質の高い回答を生成することはできなかった。
利用者の要求に応え続けるためには、RAGアーキテクチャそのものを進化させる必要がある。理想的な次世代のRAGは、単なる検索と生成の組み合わせではなく、より高度な思考プロセスを内包するべきである。具体的には、まず利用者の質問に含まれる複数の意図や視点を正確に解析し、解決すべきサブタスクへと分解する「質問意図解析」。次に、分解されたタスクに基づき、複数のAIエージェントが自律的かつ再帰的に情報収集、書き換え、評価を繰り返す「情報探索とフィードバック」のループ。そして、探索プロセス全体を記憶・評価し、次に何を探すべきかを動的に判断する「エージェント統合管理」。このような、階層的かつ動的なアーキテクチャこそが、「複合的なクエリ」に対する本質的な解決策となる。
当社は、この理想的なアーキテクチャを具現化すべく、AskDonaの次期バージョンとしてdona-rag-2.0およびdona-rag-2.5を構築した。続く第3章では、dona-rag-1.0の導入がサポート業務に与えた影響を分析し、第4章において、この次世代アーキテクチャが「複合的なクエリ」に対してどれほどの性能向上を実現したのかを、主要なRAGサービスとの比較検証を通じて定量的に実証する。
2.6 本章の結論
本章では、AskDonaと高度検索の導入後の利用動向を定量・定性的に分析した。その結果、以下の点が明らかになった。
第一に、AskDonaは利用者に有効なサポート手段として定着した。 月間の平均質問数・セッション数は安定した水準を維持し、1セッションあたりの平均質問数も約5.7件と、利用者がAskDonaを対話的に活用していることが示された。特に、利用経験の浅いユーザーほど対話数が多くなる傾向が見られ、学習・試行錯誤のツールとしても機能している可能性が示唆された。
第二に、利用の定着に伴い、利用者の要求はより高度化・複合化した。 利用者の質問目的は、単純な「情報探索」から具体的な「方法探索」へとシフトした。さらに、運用期間の経過と共に、複数の文書を横断的に調査・統合する必要がある「複合的なクエリ」の割合は約4.3倍に増加した。これは、利用者がシステムの能力を認識し、より困難な課題解決をAIに委ねるようになったこと、また、サポート窓口の一本化により、従来は有人担当者に投げていた詳細な質問がAskDonaに向けられるようになったことを示唆する。
第三に、クエリの複合化は、従来型のRAGシステムが共通して抱える構造的な限界を浮き彫りにした。 AskDona(dona-rag-1.0)において、クエリが高度化・複合化するにつれて不回答率が再び上昇した事実は、この課題を象徴している。これは特定のシステムの品質劣化を意味するのではなく、単発的な検索プロセスに依存する標準的なアーキテクチャでは、利用者が求める多角的な情報探索・統合に応えきれないという、RAG技術の一般的な課題が顕在化した結果である。
以上の分析から、実務環境で役立つRAGシステムを構築・運用するためには、基本的な検索・生成能力だけでは不十分であることが結論づけられる。利用者の習熟度や要求レベルは常に変化・向上するため、利用者の意図を深く解釈し、自律的に情報を探索・統合する高度なRAGアーキテクチャへの継続的なアップデートが不可欠であることを示唆した。
AskDonaの次期バージョン(dona-rag-2.0およびdona-rag-2.5)は、まさにこの課題に応えるために設計されたものであり、その回答精度の検証は第4章で詳述する。今後は、この次世代アーキテクチャを富岳サポートサイトへ適用し、さらに高度な利用者サポートを実現するツールとして成長させていく予定である。

レポートリスト