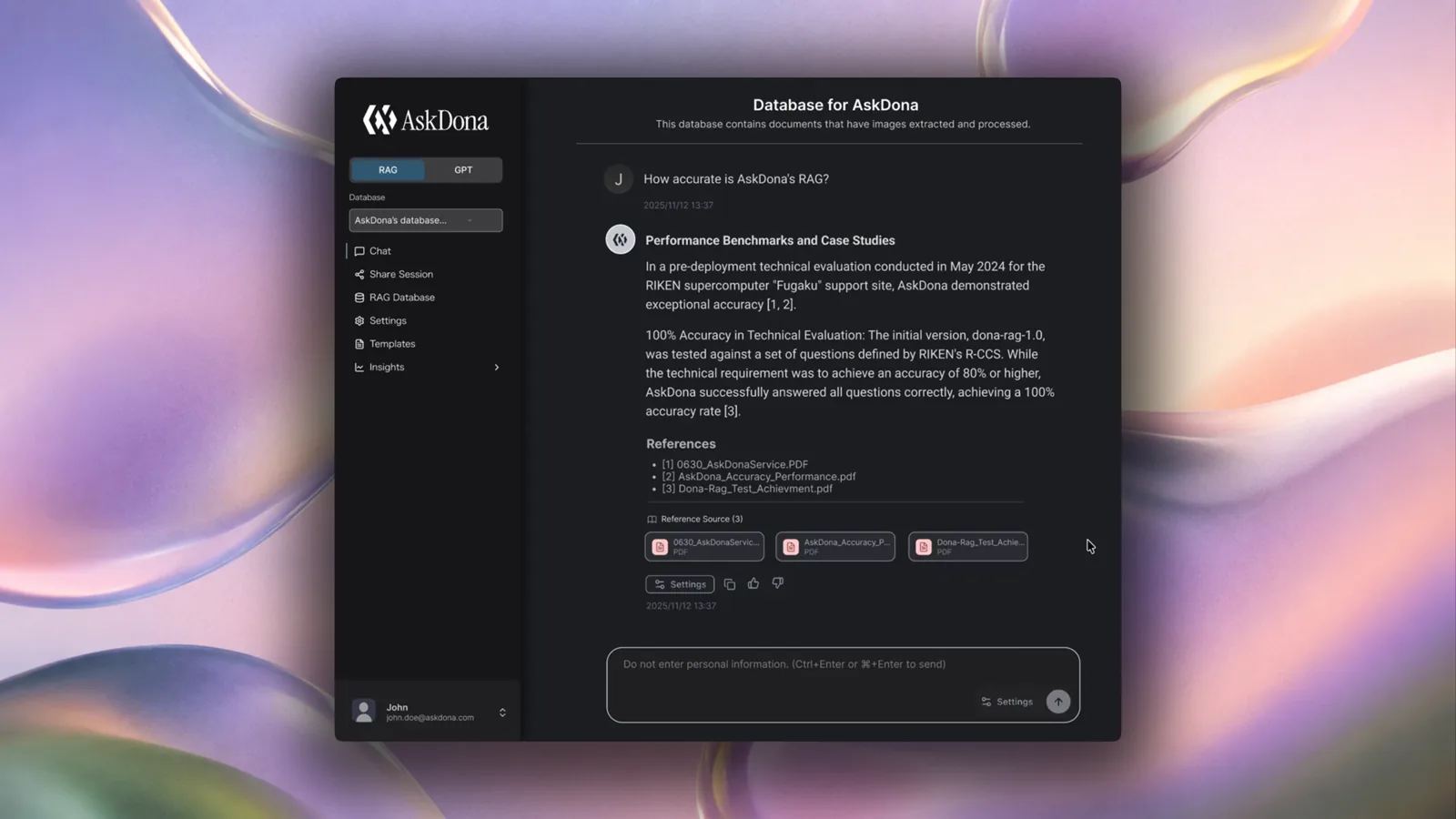






部署単位の小さなFAQではなく、全社・複数部門・複数拠点で使われる知識基盤を想定しています。Built for knowledge operations across departments, locations, and large teams — not just a small departmental FAQ.
回答から改善までFrom answers to improvement
取り込み、探し、示し、
取り込み、探し、示し、
改善する。
Ingest, search, cite,
and improve.
AskDonaは、社内資料を取り込み、AIエージェントが必要な情報を探し、根拠つきで回答します。さらに、未回答やフィードバックをもとに、知識データベースを継続的に改善できます。 AskDona ingests internal documents, lets an AI agent search for the right information, and answers with citations. Unanswered questions and feedback then become signals for continuously improving the knowledge base.
01
基盤Foundation
社内資料を、そのまま知識データベースへ。Turn internal documents into a knowledge base.
ドキュメントやHTMLなど、組織にある情報をもとに知識データベースを構築。FAQの対を作るような事前整備に時間をかけず、既存資料から始められます。Build a knowledge base from documents, HTML, and the information your organization already has. Start from existing materials without authoring FAQ pairs.
- ドキュメント
- Documents
- HTML
- 既存資料そのまま
- Existing files, as-is
- FAQ作成 不要
- No FAQ authoring
02
基盤Foundation
複雑な資料も、現場の形式のまま扱える。Works with the complex files teams actually use.
画像、テーブル、数式、スキャンPDF、ページ数の多い資料、複数タブのExcel、画像入りのPowerPointまで。OCR処理も含めて、現場に散らばる多様な情報を知識データベースの対象にできます。Images, tables, formulas, scanned PDFs, long documents, multi-tab spreadsheets, and image-rich presentations can all become part of the knowledge base, with OCR included in the ingestion process.
- 画像
- Images
- テーブル
- Tables
- 数式
- Formulas
- OCR
- スキャンPDF
- Scanned PDF
- 100GB+
- 複数タブExcel
- Multi-tab Excel
- 画像入りPPT
- Image-rich PPT
03
基盤Foundation
大規模向けの品質を、軽い準備で始める。Enterprise-grade quality, with light setup.
大規模な知識運用を想定しながら、FAQ作成や個別チューニングに時間をかけず、登録した社内資料をもとに利用を開始できます。導入の準備は軽く、回答品質は妥協しない。そのバランスを重視しています。AskDona is designed for large-scale knowledge operations while reducing the setup burden. Teams can start from registered internal documents without FAQ authoring or custom tuning — lowering preparation effort without compromising answer quality.
回答精度Answer accuracy90%+
準備工数Prep effort≈0
04
AskDonaのしくみHow AskDona works
AIエージェントが、質問を整理して探しにいく。An AI agent organizes the question and searches.
ユーザーの質問を受け取ると、AIエージェントが必要な観点を整理し、関連する情報を探索します。単純なキーワード検索ではなく、回答に必要な根拠を集めて構成します。When a user asks a question, the AI agent organizes the relevant angles and searches for supporting information — gathering the evidence needed to compose an answer, rather than relying on a flat keyword search.
05
AskDonaのしくみHow AskDona works
何を探しているのかが、見える。Make the search process visible.
AIエージェントが何を確認し、どの資料群を対象にしているのかを可視化します。ユーザーは、回答が生成されるまでの流れを追いながら、安心して利用できます。AskDona shows what the AI agent is checking and which document groups it is using. Users can follow the process behind the answer with greater confidence.
質問を分解していますDecomposing the question3つの観点に整理Split into 3 angles
関連文書を探索中Searching source docs12件の候補を評価Evaluating 12 candidates
回答を構成していますComposing the answer根拠を紐づけ中…Linking evidence…
06
退職金の計算方法を教えてHow is severance calculated?
勤続年数に応じた支給率を基本給に乗じて算出します1。役職加算は別表を参照してください2。It's the base salary times a tenure-based rate1. Role add-ons follow a separate table2.
1就業規則2024.pdf · p.42
2給与規程_別表.xlsx · Sheet 3
AskDonaのしくみHow AskDona works
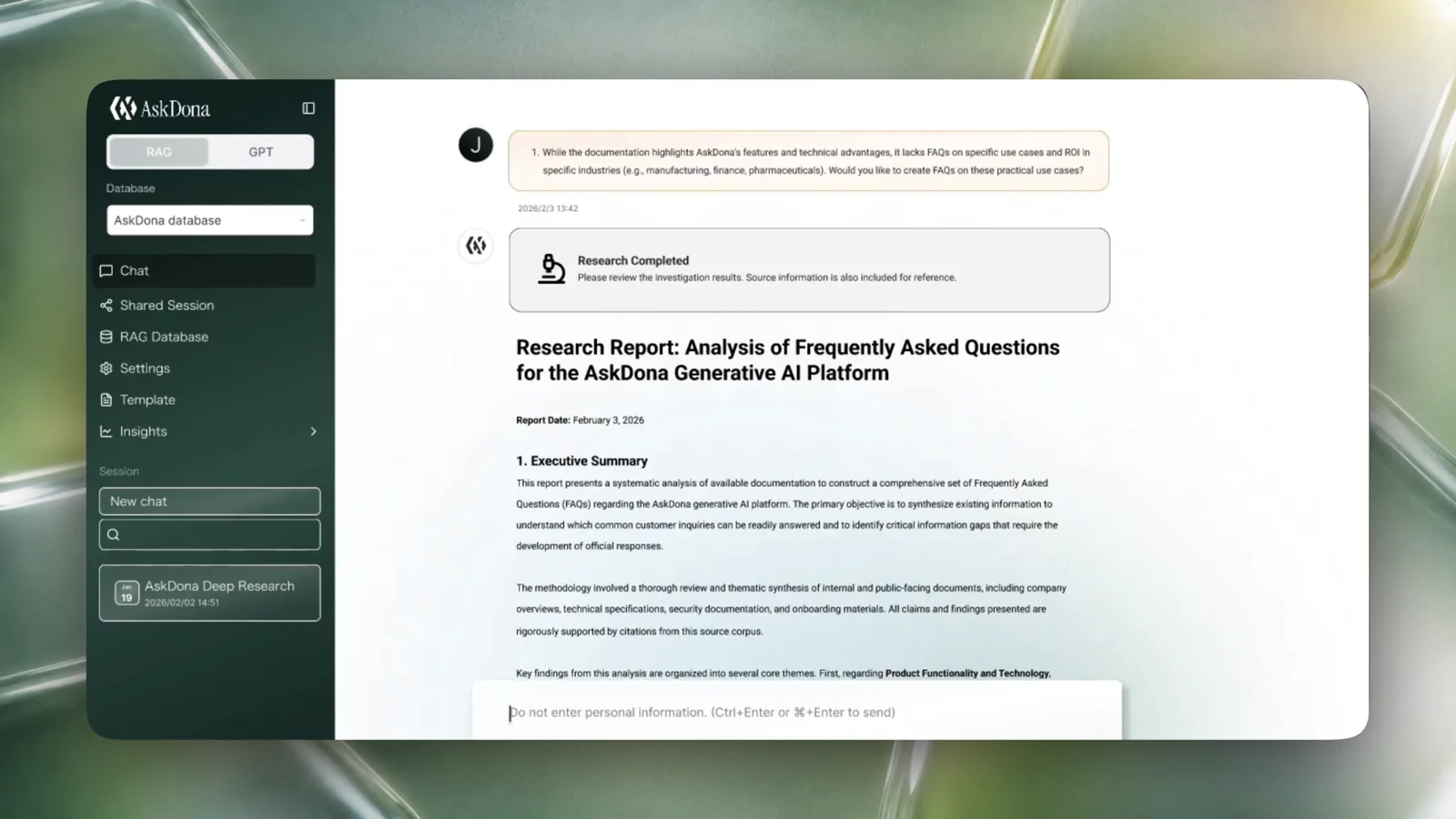
回答の根拠に、いつでも戻れる。Always return to the source.
回答には参照元の番号が付き、どの資料のどこを根拠にしたのかを確認できます。気になる回答があっても、その場で原文に戻れます。Answers include numbered citations so users can see which source was used. When something needs confirmation, they can return to the original document immediately.
07
AskDonaのしくみHow AskDona works
ユーザーの声を、改善につなげる。Turn user feedback into improvement.
回答に対するフィードバックをインサイトとして可視化。どの質問で迷いが生まれたのか、どの情報を見直すべきかを把握し、次のデータ改善につなげます。Feedback on answers becomes visible as insight. Teams can understand where users struggled, which information needs review, and what to improve next.
👍 役に立った👍 Helpful
👎 改善キュー👎 Improve queue
08
AskDonaのしくみHow AskDona works
答えられなかった質問を、見逃さない。Never lose track of unanswered questions.
「申し訳ございません」「すみません」など、回答できなかった可能性のある表現を自動検知。不足している情報を見つけ、知識データベースの改善候補として残します。AskDona detects apology-style responses that may indicate an unanswered question, helping teams identify missing information and keep it as a candidate for knowledge base improvement.
「申し訳ございません…」を検知 → 不足情報として登録Detected "I'm sorry…" → logged as missing info
09
AskDonaのしくみHow AskDona works
知識データベースを、自分たちの手で改善する。Improve the knowledge base with your own team.
不足情報やフィードバックをもとに、管理者がデータを見直し、再反映できます。外部対応を待つだけではなく、組織のスピードで知識を整えていけます。Admins can review data and redeploy improvements based on missing information and feedback. Knowledge can be refined at the organization's own pace.