
A KNOWLEDGE BASE BEHIND ASKDONA
Three ways teams get answers fast-
with data you already have
AskDona’s RAG serves as the data foundation across nearly all features.



And above all, it is designed to deliver consistently high answer accuracy.
View full report
Read the full report
High accuracy from Day 1 - with the data you already have
Many AI initiatives start with:
Data cleanup and restructuring
“AI-ready” data preparation
Long setup phases before real use
AskDona takes a different approach.
From Day 1, you can upload the data you already have and start getting accurate, reliable answers — without redesigning your data or workflows.
This immediate reliability is what allows teams to move from experimentation to real usage quickly.
For a deeper explanation of how AskDona achieves this level of accuracy, see the AskDona Architecture.
How Data Ingestion Works
1. Upload your data
After logging into the AskDona platform, you can upload your existing data directly.
Local files
Box / Google Drive (supported or planned)
Bulk upload of hundreds of files at once
Supported formats include:
Excel
CSV
Word
PowerPoint
PDF
JSON
Markdown
HTML
Images
Mixed formats are fully supported.
2. Optional: collect content from the web
For specific use cases, AskDona can automatically retrieve websites and convert them into Markdown format.
This is especially useful for:
Public guidelines and manuals
Frequently updated web content
Information spread across multiple pages
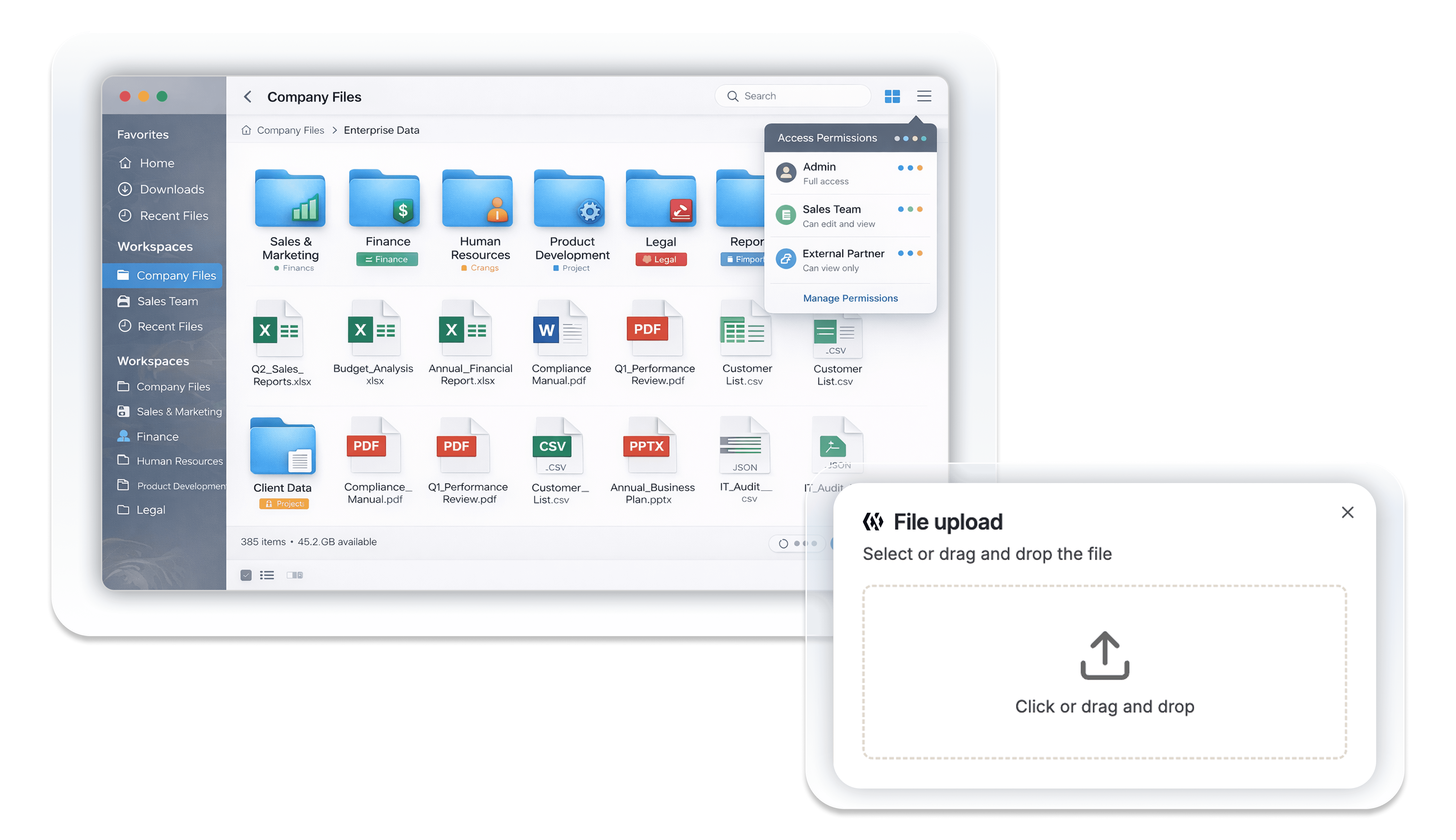
Organize Content with Metadata — At Scale
All uploaded content appears as a list in the AskDona admin interface. If needed, content can be categorized using metadata.
Single metadata update
Metadata Without the Overhead
Metadata is powerful — but often avoided because it’s time-consuming to assign.
AskDona removes that friction.
Download a CSV template
Enter metadata values in bulk
Upload the CSV to apply metadata all at once
Once assigned, metadata can be used as filter conditions during chat and analysis, helping users narrow answers by category, department, document type, and more.
Bulk metadata update
Process Once — At Scale
When metadata setup is complete, click the Process button.
AskDona automatically performs:
OCR
Chunking
Content normalization
Vectorization
All processing runs in bulk, making large-scale ingestion easy. Optimized for complex documents
For documents such as:
PDFs with many images or tables
Scientific or mathematical materials
You can select specialized extraction models, including options optimized for formulas and technical notation. Citation-first answers you can trust
Once processing is complete, your RAG knowledge base is ready.
When you start chatting:
Answers are generated using a citation-first model
Every response is grounded in explicit source documents
Accuracy is consistent and verifiable
This is evidence-based answering — not probabilistic guesswork.
One database. Many categories. No confusion.
Data is centralized for cross-search, yet context is never mixed.
This allows organizations to:
Avoid siloed databases
Maintain a single source of truth
Retrieve the right context every time
Built for real operational use

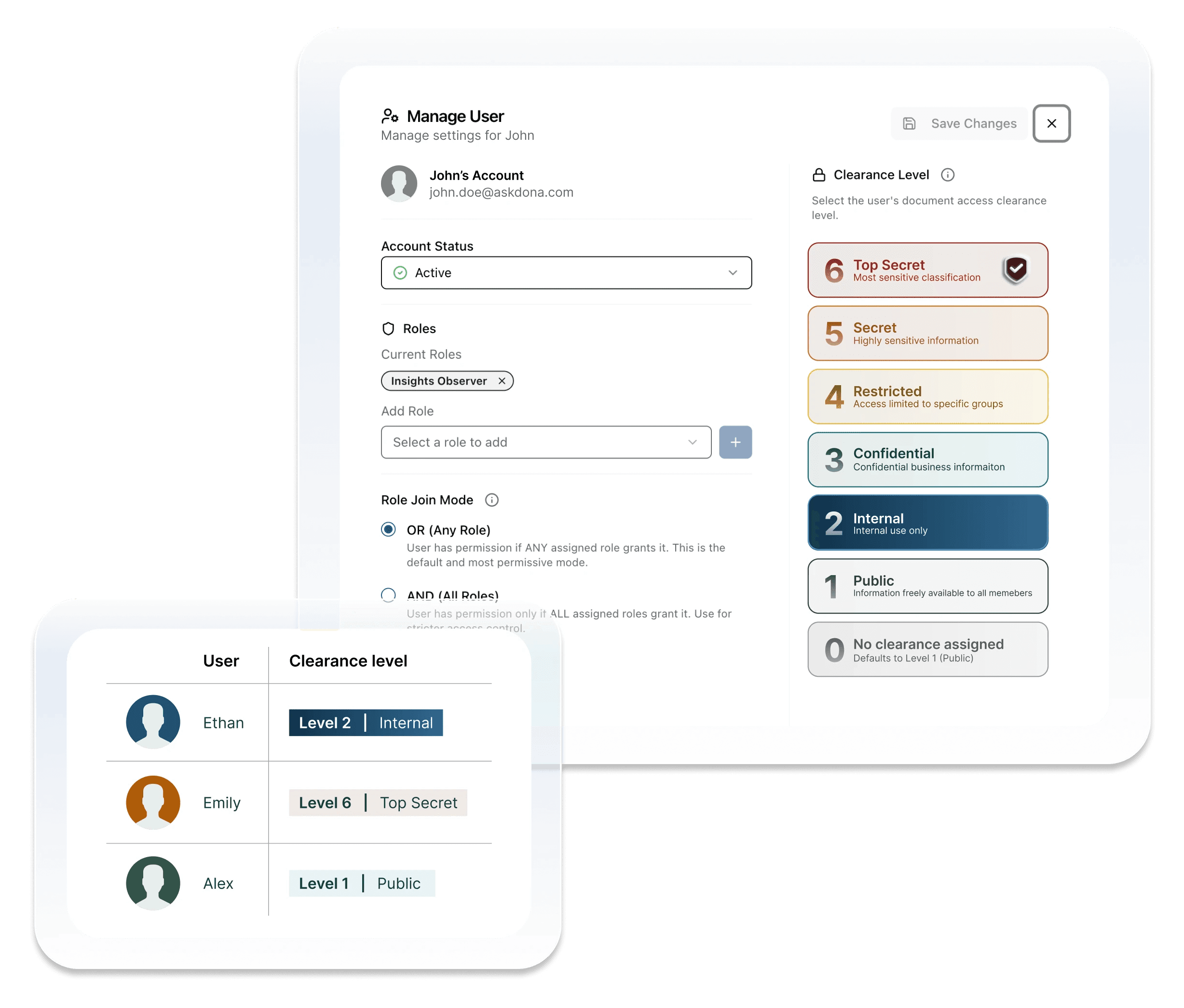
Security & Control
In real operations, data sensitivity and access control matter.
AskDona allows you to:
Assign confidentiality levels to documents
Define which user roles can access each level
Even if a user can access the database itself, AskDona will not generate answers based on documents above their permitted confidentiality level.
Access rules are enforced at the answer-generation stage.
A KNOWLEDGE BASE BEHIND ASKDONA
Three ways teams get answers fast-
with data you already have
AskDona’s RAG serves as the data foundation across nearly all features.
And above all, it is designed to deliver consistently high answer accuracy.
View full report
Read the full report
High accuracy from Day 1 - with the data you already have
Many AI initiatives start with:
Data cleanup and restructuring
“AI-ready” data preparation
Long setup phases before real use
AskDona takes a different approach.
From Day 1, you can upload the data you already have and start getting accurate, reliable answers — without redesigning your data or workflows.
This immediate reliability is what allows teams to move from experimentation to real usage quickly.
For a deeper explanation of how AskDona achieves this level of accuracy, see the AskDona Architecture.
How Data Ingestion Works
1. Upload your data
After logging into the AskDona platform, you can upload your existing data directly.
Local files
Box / Google Drive (supported or planned)
Bulk upload of hundreds of files at once
Supported formats include:
Excel
CSV
Word
PowerPoint
PDF
JSON
Markdown
HTML
Images
Mixed formats are fully supported.
2. Optional: collect content from the web
For specific use cases, AskDona can automatically retrieve websites and convert them into Markdown format.
This is especially useful for:
Public guidelines and manuals
Frequently updated web content
Information spread across multiple pages
Organize Content with Metadata — At Scale
All uploaded content appears as a list in the AskDona admin interface. If needed, content can be categorized using metadata.
Single metadata update
Metadata Without the Overhead
Metadata is powerful — but often avoided because it’s time-consuming to assign.
AskDona removes that friction.
Download a CSV template
Enter metadata values in bulk
Upload the CSV to apply metadata all at once
Once assigned, metadata can be used as filter conditions during chat and analysis, helping users narrow answers by category, department, document type, and more.
Bulk metadata update
Process Once — At Scale
When metadata setup is complete, click the Process button.
AskDona automatically performs:
OCR
Chunking
Content normalization
Vectorization
All processing runs in bulk, making large-scale ingestion easy. Optimized for complex documents
For documents such as:
PDFs with many images or tables
Scientific or mathematical materials
You can select specialized extraction models, including options optimized for formulas and technical notation. Citation-first answers you can trust
Once processing is complete, your RAG knowledge base is ready.
When you start chatting:
Answers are generated using a citation-first model
Every response is grounded in explicit source documents
Accuracy is consistent and verifiable
This is evidence-based answering — not probabilistic guesswork.
One database. Many categories. No confusion.
Data is centralized for cross-search, yet context is never mixed.
This allows organizations to:
Avoid siloed databases
Maintain a single source of truth
Retrieve the right context every time
Built for real operational use
Security & Control
In real operations, data sensitivity and access control matter.
AskDona allows you to:
Assign confidentiality levels to documents
Define which user roles can access each level
Even if a user can access the database itself, AskDona will not generate answers based on documents above their permitted confidentiality level.
Access rules are enforced at the answer-generation stage.
A KNOWLEDGE BASE BEHIND ASKDONA
Three ways teams get answers fast-
with data you already have
AskDona’s RAG serves as the data foundation across nearly all features.
And above all, it is designed to deliver consistently high answer accuracy.
View full report
Read the full report
High accuracy from Day 1 - with the data you already have
Many AI initiatives start with:
Data cleanup and restructuring
“AI-ready” data preparation
Long setup phases before real use
AskDona takes a different approach.
From Day 1, you can upload the data you already have and start getting accurate, reliable answers — without redesigning your data or workflows.
This immediate reliability is what allows teams to move from experimentation to real usage quickly.
For a deeper explanation of how AskDona achieves this level of accuracy, see the AskDona Architecture.
How Data Ingestion Works
1. Upload your data
After logging into the AskDona platform, you can upload your existing data directly.
Local files
Box / Google Drive (supported or planned)
Bulk upload of hundreds of files at once
Supported formats include:
Excel
CSV
Word
PowerPoint
PDF
JSON
Markdown
HTML
Images
Mixed formats are fully supported.
2. Optional: collect content from the web
For specific use cases, AskDona can automatically retrieve websites and convert them into Markdown format.
This is especially useful for:
Public guidelines and manuals
Frequently updated web content
Information spread across multiple pages
Organize Content with Metadata — At Scale
All uploaded content appears as a list in the AskDona admin interface. If needed, content can be categorized using metadata.
Metadata Without the Overhead
Metadata is powerful — but often avoided because it’s time-consuming to assign.
Single metadata update
Metadata Without the Overhead
AskDona removes that friction.
Download a CSV template
Enter metadata values in bulk
Upload the CSV to apply metadata all at once
Once assigned, metadata can be used as filter conditions during chat and analysis, helping users narrow answers by category, department, document type, and more.
Bulk metadata update
Process Once — At Scale
When metadata setup is complete, click the Process button.
AskDona automatically performs:
OCR
Chunking
Content normalization
Vectorization
All processing runs in bulk, making large-scale ingestion easy. Optimized for complex documents
For documents such as:
PDFs with many images or tables
Scientific or mathematical materials
You can select specialized extraction models, including options optimized for formulas and technical notation. Citation-first answers you can trust
Once processing is complete, your RAG knowledge base is ready.
When you start chatting:
Answers are generated using a citation-first model
Every response is grounded in explicit source documents
Accuracy is consistent and verifiable
This is evidence-based answering — not probabilistic guesswork.
One database. Many categories. No confusion.
Data is centralized for cross-search, yet context is never mixed.
This allows organizations to:
Avoid siloed databases
Maintain a single source of truth
Retrieve the right context every time
Built for real operational use
Security & Control
In real operations, data sensitivity and access control matter.
AskDona allows you to:
Assign confidentiality levels to documents
Define which user roles can access each level
Even if a user can access the database itself, AskDona will not generate answers based on documents above their permitted confidentiality level.
Access rules are enforced at the answer-generation stage.
Frequently asked questions
Frequently asked questions
Frequently asked questions
Will the data I upload to the RAG database be stored on a domestic server?
Yes, files uploaded to the RAG database are managed on servers within Japan.
Is the AskDona usage environment separated from other companies?
Can I use AskDona in my own cloud environment?
What are the file formats and capacity limits that can be stored in RAG?
Will internal data be used to train ChatGPT?



Start with a free consultation.
AskDona is dedicated to Redefining Roles. We empower your organization by assigning all AI-capable tasks to the technology, allowing you to focus on critical human functions and innovation.
Deep Research
Batch Analysis
Reports
Articles
Start with a free consultation.
AskDona is dedicated to Redefining Roles. We empower your organization by assigning all AI-capable tasks to the technology, allowing you to focus on critical human functions and innovation.
Deep Research
Batch Analysis
Reports
Articles
Start with a free consultation.
AskDona is dedicated to Redefining Roles. We empower your organization by assigning all AI-capable tasks to the technology, allowing you to focus on critical human functions and innovation.
Deep Research
Batch Analysis
Reports
Articles
A KNOWLEDGE BASE BEHIND ASKDONA
Three ways teams get answers fast-
with data you already have
AskDona’s RAG serves as the data foundation across nearly all features.
And above all, it is designed to deliver consistently high answer accuracy.
View full report
Read the full report
High accuracy from Day 1 - with the data you already have
Many AI initiatives start with:
Data cleanup and restructuring
“AI-ready” data preparation
Long setup phases before real use
AskDona takes a different approach.
From Day 1, you can upload the data you already have and start getting accurate, reliable answers — without redesigning your data or workflows.
This immediate reliability is what allows teams to move from experimentation to real usage quickly.
For a deeper explanation of how AskDona achieves this level of accuracy, see the AskDona Architecture.
How Data Ingestion Works
1. Upload your data
After logging into the AskDona platform, you can upload your existing data directly.
Local files
Box / Google Drive (supported or planned)
Bulk upload of hundreds of files at once
Supported formats include:
Excel
CSV
Word
PowerPoint
PDF
JSON
Markdown
HTML
Images
Mixed formats are fully supported.
2. Optional: collect content from the web
For specific use cases, AskDona can automatically retrieve websites and convert them into Markdown format.
This is especially useful for:
Public guidelines and manuals
Frequently updated web content
Information spread across multiple pages
Organize Content with Metadata — At Scale
All uploaded content appears as a list in the AskDona admin interface. If needed, content can be categorized using metadata.
Metadata Without the Overhead
Metadata is powerful — but often avoided because it’s time-consuming to assign.
Single metadata update
AskDona removes that friction.
Download a CSV template
Enter metadata values in bulk
Upload the CSV to apply metadata all at once
Once assigned, metadata can be used as filter conditions during chat and analysis, helping users narrow answers by category, department, document type, and more.
Bulk metadata update
Process Once — At Scale
When metadata setup is complete, click the Process button.
AskDona automatically performs:
OCR
Chunking
Content normalization
Vectorization
All processing runs in bulk, making large-scale ingestion easy. Optimized for complex documents
For documents such as:
PDFs with many images or tables
Scientific or mathematical materials
You can select specialized extraction models, including options optimized for formulas and technical notation. Citation-first answers you can trust
Once processing is complete, your RAG knowledge base is ready.
When you start chatting:
Answers are generated using a citation-first model
Every response is grounded in explicit source documents
Accuracy is consistent and verifiable
This is evidence-based answering — not probabilistic guesswork.
One database. Many categories. No confusion.
Data is centralized for cross-search, yet context is never mixed.
This allows organizations to:
Avoid siloed databases
Maintain a single source of truth
Retrieve the right context every time
Built for real operational use
Security & Control
In real operations, data sensitivity and access control matter.
AskDona allows you to:
Assign confidentiality levels to documents
Define which user roles can access each level
Even if a user can access the database itself, AskDona will not generate answers based on documents above their permitted confidentiality level.
Access rules are enforced at the answer-generation stage.
