Model 01 情報抽出モデル Information Extraction Model
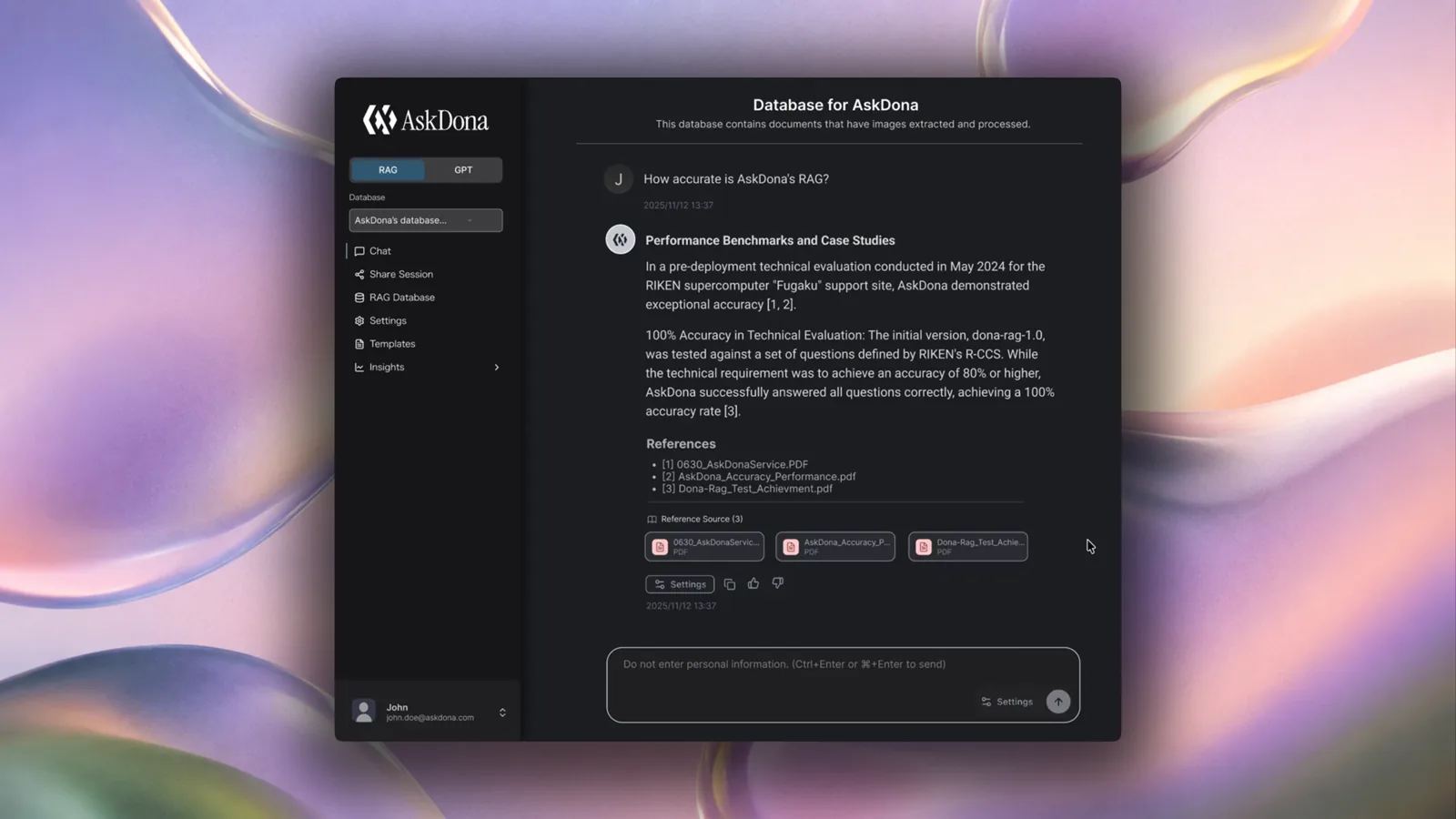
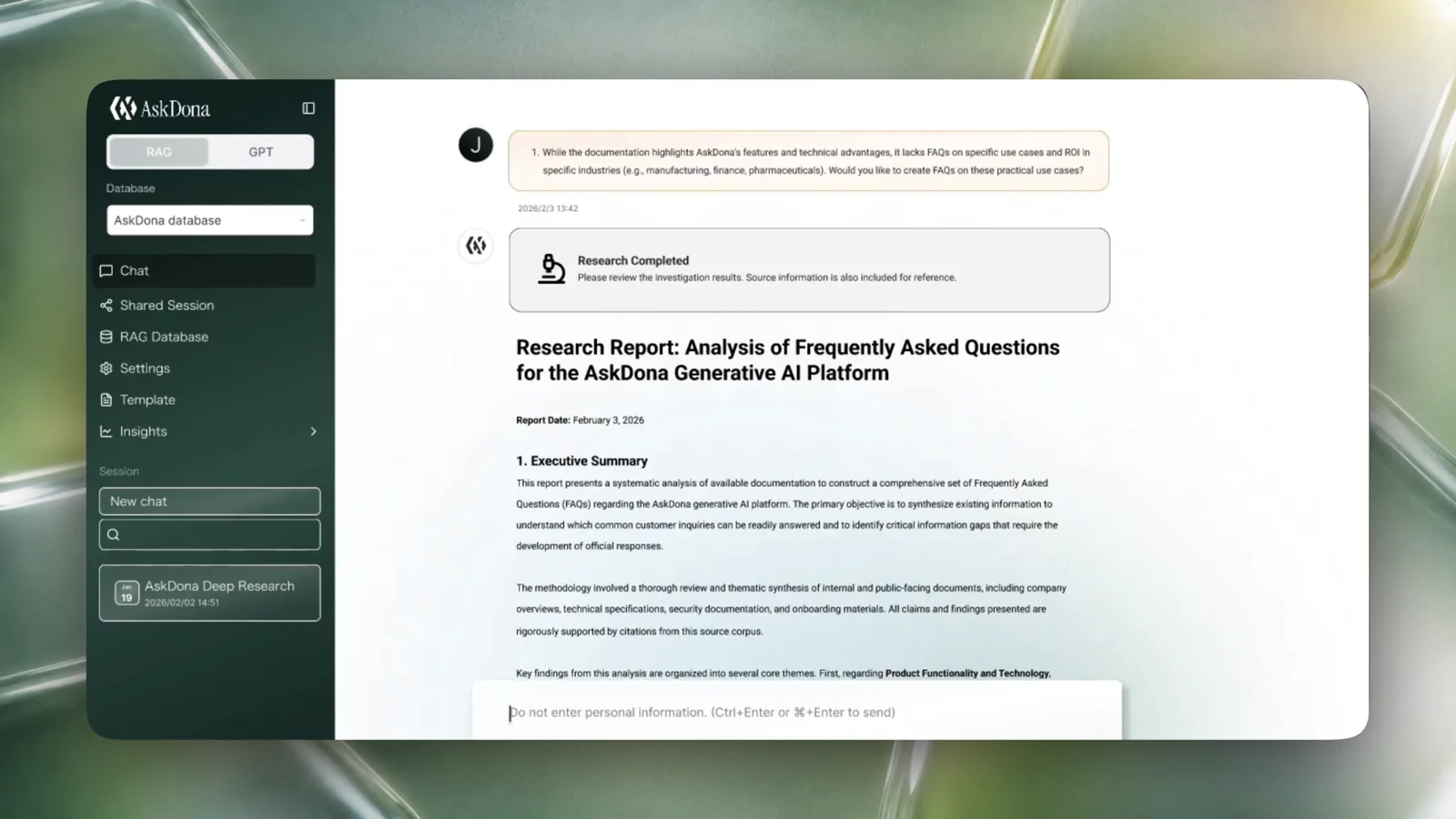
手元のドキュメントを「アップロード」し「処理」を実行すると、ドキュメント内のテキストだけでなく、画像、表、図、グラフなどを含む情報を抽出します(情報抽出モデル:Information Extraction Model)。画像については、周辺テキストの読み取り(OCR)にとどまらず、画像の意味や、矢印・グラフ・表などの要素間の関係性も解析し、内容を理解したうえでデータを抽出します。また、数式や化学式にも対応しているため、学術論文や研究データの内容も正確に取り込めます。さらに、組織固有の固有名詞を用語集として登録することで、ナレッジグラフのような関係性を伝えられる構造でデータを抽出できる仕組みも備えています。 When you "upload" the documents at hand and click "process," the system extracts information including text, images, tables, figures, and graphs contained in the document (Information extraction model). The model not only reads the surrounding text of images, but can also interpret the meaning of the images, the relationships between arrows, graphs, and tables, understand their semantics, and store them as data. It also supports mathematical formulas and chemical formulas, enabling accurate reading of academic papers and research data. In addition, by registering proper nouns specific to the organization as a glossary, the system is equipped with a mechanism that allows data to be extracted in a structure capable of conveying relationships like a knowledge graph.