





1. はじめに
RAG(Retrieval-Augmented Generation, 検索拡張生成)を評価する際、業界で広く用いられている指標は「精度N%」である。すなわち、事前に正答(ゴールドアンサー)を用意したテストクエリ集合(例えば100件)を準備し、システムの各回答が正答と一致しているかを人手またはLLM-as-a-Judgeで判定し、一致した件数の割合を算出する方法である。多くの商用RAGベンダーが提示する「精度N%」はこの方法に基づく。もっとも、faithfulnessやcontext relevance等を分けて測る評価フレームワーク(RAGAS, ARESなど)も、以前から存在する。それでも、RAGベンダーがマーケティングやセールスの場で前面に出すのは、実態として「精度N%」という単一の数値であることが多い。本稿が問うのは、これらの評価軸のいずれとも直交する視点である。
本稿で論じるのは、複数の本番デプロイを運用する中で繰り返し観察してきたことである。すなわち、この「精度N%」中心の評価が、本番運用におけるRAGパイプラインの最も重要な評価視点を捉え損ねている、という点だ。具体的には、特定のクラスのクエリは個別の精度の問題ではなく、パイプラインがそのクラスのクエリを処理する仕組み自体を備えていないという構造的理由により、正答を提供できない。本稿ではこの現象をStructural Blind Spotsと呼ぶ。
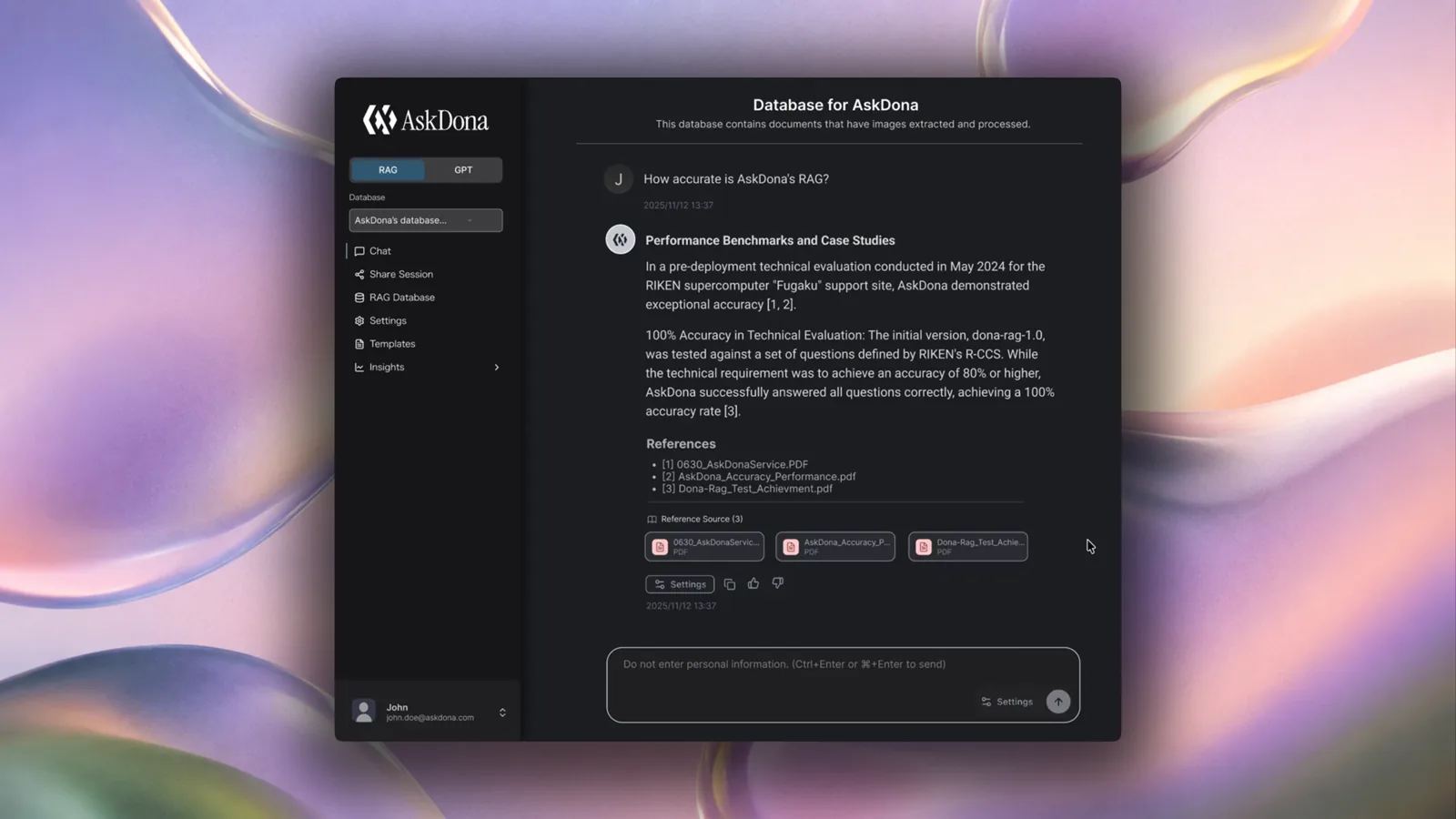
GFLOPSはエンタープライズ向けナレッジプラットフォームAskDonaを運用しており、理化学研究所 計算科学研究センター(R-CCS)で稼働する公式ポータル「スパコン成果ナビ」、およびスーパーコンピュータ「富岳」の利用者向け富岳サポートサイトに組み込まれた一次問い合わせ対応チャットボットを含む、複数の本番デプロイから、Structural Blind Spotsの具体例と測定方法に関する経験を蓄積してきた。本稿はその問題意識の概略を提示するものであり、形式的に厳密な議論および評価フレームワーク全体は、今後公開予定である。
2.「精度N%」が見落とすもの
この「精度N%」指標を形式的に表現すると、パイプライン P とテストクエリ集合 Qtest に対し、
となる。ここで âP(q) はパイプライン P がクエリ q に対して返す生成された回答、a∗(q) は事前定義された正答、𝟙[·] はインジケータ関数、≈ は何らかの一致判定(人手による評価、LLM-as-a-Judgeなど)を表す。
この指標は、二つの暗黙の前提に依拠している。
前提1: 各クエリに対する正答 a∗(q) が、信頼に足る品質で事前定義されている。
前提2: テストクエリ集合 Qtest が、本番運用で実際に出現するクエリの分布を代表している。
実運用ではこのいずれも自明ではない。前提1については、a∗(q) は本当の正解との一致が保証されているわけではなく、正答を定義した人間(またはLLM)が正答だと信じたものに過ぎない。この乖離は、評価指標に二方向の歪みをもたらす。コーパス(RAGの回答情報源として事前に指定、処理されたドキュメント等のデータ)を深く理解した人間でなければ気づかない情報を見落とした、誤っていないが不十分な a∗(q) が定義されたとき、それと同様に不十分なシステム回答 âP(q) は「正答」と判定され(優れているとは言えないRAGが優れていると評価される)、逆に、優れたRAGパイプラインが生成したより充実した回答 âP(q) は、不十分な a∗(q) から乖離しているがゆえに「不正解」と判定される(優れたRAGが過小評価される)。すなわち、評価の天井は正答の品質によって規定され、その天井を超える回答は構造的に検出できない。「精度N%」を最適化する圧力は、結果として正答に近づくようシステムを調整する圧力に転化し、真の回答品質の向上から遠ざかる。
さらに前提1の問題は、評価者の能力という偶発的な問題に留まらない。本番運用されるRAGの評価には、構造的に困難な評価可能性の問題がある。RAGの回答を生成するLLMそのものが学習した知識から回答を提供した可能性を排除してRAGパイプライン自体の性能を評価するには、評価対象のコーパスが公開データではなくクローズドなデータである必要がある。しかしクローズドであるからこそ、そのコーパスについて「適切なゴールドアンサーとは何か」を定義でき、生成された回答が「正確かつ十分」かを判定できる人間は、コーパスの所有者周辺に極めて限定される。「精度N%」という主張は、この評価可能性の制約の下で発せられている。
前提2は、本稿の主題に直接つながる。多くの公開ベンチマークは、ベンチマーク設計者が想定したクラスのクエリで Qtest を構成している。その上で精度N%を達成しても、本番運用においてQtest がカバーしていないクラスのクエリが出現した場合、システムの挙動は精度数値から予測できない。
本番運用で実際にどのようなクラスのクエリが出現するかは、運用するコーパス・対象ユーザー・サービスの目的によって大きく異なる。汎用ベンチマーク上の精度が、特定のユースケースにおける運用品質を予測する保証はない。ここでの問題は、本稿が次節以降でStructural Blind Spotsとして形式化する論点の出発点となる。
3. 構造的失敗の一例
「スパコン成果ナビ」は、R-CCSがHPCI公開成果報告書(2012〜2024年度)とJHPCN最終報告書(2011〜2024年度)あわせて6,558件のPDFをAskDonaに取り込んで構築した、過去の研究内容を自然言語で検索・対話できる公式サービスである。
このサービスのある利用者は、次のように質問した。
「スーパーコンピュータ富岳を100万時間以上利用した課題はありますか?」
質問の対象となる情報は、コーパス内に確実に存在していた。HPCI成果報告書の第1ページには、機関名・資源名・割当ノード時間・使用ノード時間が記載された構造化テーブルが含まれている。データは、ある。
それでも当初のシステムは答えられなかった。富岳の利用課題に関する複数の段落を含む流暢な回答が返ったが、「100万時間以上」という閾値を満たす課題の集合を提示することはなかった。
この失敗はLLMの能力不足ではなく、retrievalの精度不足でもない。失敗の本質は、本番運用されるRAGパイプラインの多くが、条件を満たす完全な集合を返す必要があるクエリ(top-k、count、sum、comparison、filter+aggregateなどの集約クエリ)に対し、構造的に対応する処理経路を備えていないことにある。これは個別の精度の改善で解決する種類の問題ではない。
このような構造的失敗は、集約クエリに限らない。複数文書を統合する必要があるクエリ、時系列の変化を捉える必要があるクエリ、否定や除外を含む条件を扱うクエリ、質問自体が曖昧で逆質問を要するクエリ、そもそもコーパス外で「答えられない」と返すのが正解のクエリ。それぞれに対し、パイプライン側で異なる種類の専用の処理が必要となる。
4. Structural Blind Spots
以上の観察から、RAGパイプラインの本番運用において評価すべき問いは、次のように再定式化できる。
「実運用で出現するクエリの各クラスに対して、当該パイプラインは構造的に対応する仕組みを備えているか。」
本稿ではこの問いをStructural Blind Spotsと呼ぶ。
なお「カバー(coverage)」という語は、RAGの文献では検索が関連文書をどれだけ拾えたか(retrieval recall / コーパス網羅)を指して用いられることが多いが、本稿の用法はそれと異なる。ここで問うのは、クエリの各クラスに対し、パイプラインがそれを処理する専用の機構を備えているか、という対応可能性であって、検索の網羅率ではない。
形式的には、クエリ全体に対する有限の分類体系 𝒯 を考える(以下では記述を簡明にするため、各クエリがちょうど一つのクラスに属する相互排他的なhard分類を仮定する。複数クラスへの所属を許すsoftな分類への一般化は、評価フレームワーク全体とともに今後扱う)。各クラス τ ∈ 𝒯 の本番運用における出現確率 π(τ) を考え、Στ ∈ 𝒯 π(τ) = 1 が成り立つとする。パイプライン P が構造的にカバーするクラスの集合を 𝒞(P) ⊆ 𝒯 と書くと、Structural Blind Spotsの問いは、構造的にカバーされていないクラスの確率質量
をどう特徴付け、どう減らすかとして表現できる。Gap(P; π) が大きいということは、本番運用で出現するクエリの確率質量のうち、無視できない部分がパイプライン P では構造的に処理できないクラスに属していることを意味する。
「精度N%」が「個別クエリへの回答品質」を測るのに対し、Structural Blind Spotsは「クエリクラスへの対応可能性」を問う。ただし両者は対等ではない。対応可能性は、精度に論理的に先立つ。τ ∉ 𝒞(P) のクラスに属するクエリでは、精度を改善することは原理的に不可能であり、𝒞(P) を拡張するしかない。逆に、τ ∈ 𝒞(P) のクラスに対しても個別の回答品質は別途測られる必要がある。
この関係は、精度N%に限らず、多次元評価フレームワークに対しても同様に成り立つ。RAGASはfaithfulness・answer relevancy・context precision / recallを、主に参照不要(reference-free)のLLMベース指標として測る。ARESはcontext relevance・answer faithfulness・answer relevanceを、合成データで微調整した軽量判定器と、少数の人手アノテーションによるprediction-powered inferenceを用いて、統計的な信頼区間つきで推定する。RAGCheckerは応答をclaim単位に分解するentailmentチェックにより、retrieverとgeneratorを細粒度に診断する。これらはいずれも、与えられたクエリに対する検索と生成の品質、すなわち τ ∈ 𝒞(P) のクラス内部の品質を精緻に測るものであり、𝒞(P) そのもの(どのクラスに対応する処理機構が存在するか)を問うものではない。本稿の視点はこれらと競合せず、むしろそれらが暗黙に前提とする「そのクラスは扱える」という土台自体を対象化する点で、直交する。
Structural Blind Spotsの観点を導入することの実務上の含意は、次のとおりである。
- RAGプロダクトの評価にあたって、𝒞(P) がどのようなクラスを含むかを「精度N%」と独立に問う必要がある
- 本番運用におけるクエリクラスの分布 π(τ) は、汎用ベンチマークが想定する分布とは異なる可能性が高く、実運用ログによる経験的観察に依拠する必要がある(ただしsurvivor biasやユーザーのself-censorshipの補正は非自明であり、推定法そのものが独立の研究課題となる)
- RAGベンダーには、自社プロダクトの 𝒞(P) を明示する責任がある(ただしその明示は自己申告であり、第三者がそれを検証する方法自体が、§2 で述べた評価可能性の制約のもとで未解決の課題として残る)
クラス分類 𝒯 の具体的な体系、𝒞(P) の形式的な判定方法、π(τ) の経験的推定法、および評価フレームワーク全体については、今後公開予定である。なお、𝒞(P) のoperational definitionには、構造的判定(専用処理経路の有無)と経験的判定(クラス内成功率の閾値)の二つの方向がありうる。本稿はこの定義そのものを開かれた問いとして扱い、形式的選択は後続論文に委ねる。
5. 取り組み
GFLOPSは、AskDonaの本番運用において観察された複数のクエリクラスに対し、それぞれを処理する専用の仕組みの研究と開発を進めている。
スパコン成果ナビにおける集約クエリへの対応として、コーパスに含まれる数値情報を抽出し、クエリ時に集約処理にルーティングする専用パイプラインを開発した。この仕組みの実装と評価については、R-CCSとの共著研究として取り組んでいる。
クエリクラスの体系化と評価フレームワーク全体については、AskDonaの本番ログによる実証を伴う形で研究を進めている。
GFLOPSについて
GFLOPSはエンタープライズ向けナレッジプラットフォームAskDonaの開発・運用を行う。主な公開導入実績として、理化学研究所 計算科学研究センター(R-CCS)のスーパーコンピュータ「富岳」サポートサイトに組み込まれた利用者向け一次問い合わせ対応チャットボットへの採用(2024年7月開始、2025年2月全面採用)、およびHPCI/JHPCN全6,558件の成果報告書を対象とするR-CCS公式ポータル「スパコン成果ナビ」の運用がある。
1. Introduction
Retrieval-Augmented Generation (RAG) is, in practice, still evaluated by "N% accuracy": prepare a test set of queries with predefined ground-truth answers (say, 100 queries), then report the fraction for which the system's response is judged to match the ground truth — either by human evaluators or by an LLM-as-a-Judge. The "N% accuracy" figures advertised by commercial RAG vendors rest on this method. To be sure, evaluation frameworks that score answer quality along several axes, such as faithfulness and context relevance (RAGAS, ARES, and others), have existed for some time. Even so, what RAG vendors put front and center in marketing and sales is, in practice, the single "N% accuracy" figure. The question this article raises is orthogonal to all of these axes.
What we argue, drawing on what we have repeatedly observed across multiple production deployments, is that "N% accuracy", taken alone, misses the most important dimension along which production RAG pipelines should be evaluated. Specifically, certain classes of queries fail not because of individual accuracy issues but because the pipeline lacks the mechanism required to handle that class of query at all. We call this phenomenon Structural Blind Spots.
GFLOPS operates AskDona, an enterprise knowledge platform powering, among others, the official R-CCS portal Supercomputer Outcome Navigator (スパコン成果ナビ) and the first-line inquiry support chatbot embedded in the Fugaku support site for users of the Fugaku supercomputer, both at the RIKEN Center for Computational Science (R-CCS). Across these and other production deployments we have accumulated concrete observations of Structural Blind Spots and of how to measure them. This article presents an outline of that problem; a formal treatment and a full evaluation framework are forthcoming.
2. What "N% accuracy" misses
Written formally, "N% accuracy" for a pipeline P on a test query set Qtest is
Here âP(q) is the response the pipeline returns for query q, a∗(q) is the predefined ground-truth answer, 𝟙[·] is the indicator function, and ≈ denotes some form of match — typically human evaluation or LLM-as-a-Judge.
This indicator rests on two implicit assumptions.
Assumption 1. Each a∗(q) has been defined with sufficient quality to serve as a reference.
Assumption 2. The test set Qtest is representative of the query distribution that the pipeline will actually face in production.
Neither is automatic in deployment. Under Assumption 1, a∗(q) is not guaranteed to match the true correct answer — it is merely what the human (or LLM) who defined it believed to be correct. This gap produces a two-sided distortion in the metric. When an a∗(q) is technically correct but incomplete — missing information that only someone deeply familiar with the corpus would surface — a similarly impoverished system response âP(q) is judged "correct" (underwhelming RAG systems escape detection), while a capable RAG pipeline producing a richer, more complete âP(q) is penalized for diverging from the impoverished ground truth (strong RAG systems are systematically underrated). The ceiling of evaluation is set by the quality of the ground truth, and any response that exceeds that ceiling is structurally invisible. The pressure to optimize "N% accuracy" therefore degenerates into pressure to track the ground truth rather than to genuinely improve answer quality.
The problem with Assumption 1 runs deeper than the contingent capability of the evaluator. Evaluating a production RAG system involves a structural epistemological difficulty. To isolate RAG's own performance from leakage through the LLM's training data, the evaluation corpus must be closed (non-public) data rather than publicly available content. But it is precisely because the corpus is closed that the set of people qualified to define what counts as a proper ground-truth answer — and to judge whether a generated response is accurate and sufficient — is narrowly restricted to those around the corpus owner. In other words, the very conditions that make meaningful RAG evaluation possible structurally constrain the existence of independent evaluators. Every "N% accuracy" figure is reported under this epistemological constraint.
Assumption 2 connects directly to the subject of this article. Public RAG benchmarks are constructed from query classes that the benchmark designers had in mind. Achieving N% accuracy on such a benchmark says little about how the pipeline behaves on query classes that the benchmark does not cover — yet such classes are exactly what production traffic tends to include. Which classes appear in production depends heavily on the corpus, the user population, and the purpose of the service. General-purpose benchmark scores do not, in general, predict deployment quality for a specific use case.
3. An example of structural failure
The Supercomputer Outcome Navigator is the official R-CCS service for which R-CCS ingested 6,558 PDFs into AskDona: HPCI (Japan's national high-performance computing infrastructure program) public outcome reports (FY2012–FY2024) and JHPCN (the interdisciplinary HPC research network) final reports (FY2011–FY2024). It enables natural-language search and dialogue over past research outcomes.
A user of the service recently asked:
"Are there any projects that used Supercomputer Fugaku for more than 1 million node-hours?"
The information needed to answer this question was unambiguously present in the corpus. Every HPCI outcome report carries, on its first page, a structured table of institution, resource, allocated node-hours, and used node-hours. The data was there.
And yet the system, as initially deployed, could not answer. It returned a fluent paragraph mentioning several Fugaku projects qualitatively, but it did not identify the set of projects that crossed the threshold.
This failure was not a shortcoming of the LLM, nor of retrieval precision. The failure was structural. Most production RAG pipelines lack any dedicated handling for queries that require the complete set of items satisfying a condition: top-k, count, sum, comparison, filter-plus-aggregate, and similar aggregation queries. No amount of per-query accuracy improvement on the existing pipeline solves this class of failure.
The same kind of structural failure extends beyond aggregation. Queries that require synthesizing across multiple documents; queries that require detecting change over time; queries with negation or exclusion; queries that are themselves ambiguous and demand clarification; queries whose correct answer is "I cannot answer because the corpus does not cover this." Each of these requires a different mechanism at the pipeline level.
Popular open-source RAG frameworks model the pipeline as a single retrieve-then-generate loop. Aggregation queries, along with the other classes above, expose the limit of that assumption: they require pipeline-level structure that a single loop cannot provide.
Structural failures of this kind are not confined to research-corpus deployments; they appear equally in enterprise document workflows. JSOL Corporation (an NTT Data and SMBC Group company) previously spent approximately 4,300 person-hours per year (about 570 person-days) on a 400-item system risk assessment workflow that requires conditional aggregation and evaluative judgment across multiple documents — a workload that standard RAG pipelines cannot address structurally. GFLOPS automated this workflow using AskDona's Batch Assessment, our patented evaluation-agent feature, which JSOL began offering as a commercial solution to its enterprise customers in December 2025. The structural blind spots encountered in research-corpus search recur, in different forms, across enterprise operations.
4. Structural Blind Spots
The observations above let us reformulate the evaluation question for production RAG:
For each class of query that appears in production, does the pipeline possess a mechanism that handles that class structurally?
We call this Structural Blind Spots.
A note on terminology: by "coverage" here we do not mean how many relevant documents retrieval manages to surface (retrieval recall, or corpus coverage), the sense the word usually carries in the RAG literature. We mean whether the pipeline possesses a mechanism to handle a given class of query; that is, capability, not retrieval recall.
Formally, consider a finite taxonomy 𝒯 over queries (for simplicity we assume a hard partition, in which each query belongs to exactly one class; the generalization to a soft assignment, where a query may belong to multiple classes, is left to the full framework). Let π(τ) denote the probability that a query of class τ ∈ 𝒯 appears in production, with Στ ∈ 𝒯 π(τ) = 1. Let 𝒞(P) ⊆ 𝒯 denote the set of classes that pipeline P structurally covers. Then Structural Blind Spots is the problem of characterizing and reducing the gap mass
A large Gap(P; π) means that a non-trivial share of production query mass falls into classes that pipeline P cannot handle structurally, regardless of how well it performs on the classes it does cover.
"N% accuracy" and Structural Blind Spots are not on equal footing. Where "N% accuracy" measures response quality on individual queries, Structural Blind Spots asks about class-level capability, and capability coverage is logically prior to accuracy. For queries with τ ∉ 𝒞(P), improving per-query accuracy is in principle impossible; the only remedy is to extend 𝒞(P). Conversely, for classes already in 𝒞(P), per-query quality must still be measured separately.
This relationship holds not only for "N% accuracy" but for richer, multi-axis evaluation frameworks. RAGAS measures faithfulness, answer relevancy, and context precision / recall as largely reference-free, LLM-based metrics. ARES estimates context relevance, answer faithfulness, and answer relevance using lightweight judge models fine-tuned on synthetic data, combined with prediction-powered inference over a small human-annotated set to produce statistically bounded estimates. RAGChecker performs claim-level entailment checking, decomposing a response into individual claims to diagnose the retriever and the generator at fine granularity. Each of these measures the quality of retrieval and generation for a given query, namely quality within a class τ ∈ 𝒞(P), and none of them asks about 𝒞(P) itself, that is, which classes a processing mechanism exists for at all. The lens proposed here does not compete with them; it is orthogonal, taking as its object the very assumption they presuppose, that the class is one the pipeline can handle.
Several implications follow for practitioners:
- RAG products must be evaluated by what 𝒞(P) contains, independently of "N% accuracy" figures.
- The class distribution π(τ) in production may differ significantly from the distribution assumed by any general-purpose benchmark, and must therefore be estimated empirically from real deployment logs — where correcting for survivor bias and user self-censorship is itself non-trivial and constitutes a research problem in its own right.
- RAG vendors carry a responsibility to make 𝒞(P) for their own product explicit, though such disclosure is self-reported, and how a third party could independently verify it remains, under the epistemological constraint noted in Section 2, an open problem.
A concrete class taxonomy 𝒯, a formal procedure for determining 𝒞(P), an empirical method for estimating π(τ), and the full evaluation framework are all forthcoming. We note that an operational definition of 𝒞(P) can take either of two directions — a structural criterion (does a dedicated processing path exist for the class?) or an empirical one (does the class meet a success-rate threshold?). We treat this definitional choice as an open question and leave its formal resolution to subsequent work.
5. What we're building
GFLOPS is actively developing mechanisms for the multiple query classes observed in AskDona's production deployments.
For the aggregation class on the Supercomputer Outcome Navigator deployment, we have built and deployed a component that extracts structured numerical information at ingestion time and routes aggregation queries to that structured store at query time. Implementation and evaluation of this component are forthcoming as joint work with R-CCS, scheduled for publication in late 2026.
The systematic taxonomy of query classes, together with the full evaluation framework grounded in empirical analysis of AskDona's production logs, is also forthcoming.
About GFLOPS
GFLOPS develops and operates AskDona, an enterprise knowledge platform. Public deployments include the first-line inquiry support chatbot embedded in the Fugaku support site at the RIKEN Center for Computational Science (R-CCS), in operation since July 2024 and fully adopted by R-CCS in February 2025, and the Supercomputer Outcome Navigator — the official R-CCS portal covering all 6,558 HPCI/JHPCN outcome reports.
For enterprise use, JSOL Corporation (an NTT Data and SMBC Group company) has automated its own 400-item annual system risk assessment workflow — previously consuming approximately 4,300 person-hours (about 570 person-days) per year — using AskDona's patented evaluation-agent feature Batch Assessment, which JSOL began offering as a commercial solution to its enterprise customers in December 2025.